
2010年12月13日 月曜日 [長年日記]
_ [Perl] ライトノベルのあらすじを使って遊ぶ
「ライトノベルのあらすじからトレンドを知ることができるか」を読んで、同じようにやってみました。自分、Perlしか使えないので、こちらはPerlで。
まず、「ラノベの杜 - DB検索」のデータを元にアマゾンからあらすじのテキストを取ってきます。とりあえずサンプルとしてdengeki-bunko.tsvをダウンロードします。
ダウンロードしたtsvファイルは、後々の事を考えてUTF-8に変換しておきます。
nkf -S -w dengeki-bunko.tsv > dengeki-bunko.utf-8.tsv
実験として、とりあえず「とある魔術の禁書目録」でやってみましょう。
grep 'とある魔術の禁書目録' dengeki-bunko.utf-8.tsv > toaru.tsv
「とある魔術の禁書目録」のデータだけを取り出したtoaru.tsvができました。このファイルの中からISBNコードを取り出し、このISBNコードからアマゾンの該当ページを取ってきて、その中からあらすじ部分を抽出します。そのために作ったスクリプトがget_amazon_data.plになります。このスクリプトでは抽出したあらすじテキストは入力ファイルの各行の末尾に追加して標準出力に書き出しますので、出力ファイルにリダイレクトしてください。なお、このスクリプト、昨今の事情を鑑みて1件データを取ってくると3秒待つようになっています。うまく取れなかったときは10秒待って取り直しを10回まで繰り返して、それでもダメだった場合はHTTPのステータスコードをあらすじテキストの代わりに記録するようになってます。そういうのが混じってる場合は手作業で直してやってくださいね。
ちなみに、2007年以降に発行された書籍は13桁のISBNコードが付与されているのですが、なぜかアマゾンでは存在しない10桁のISBNコードで書籍を指定する形になっています。ISBNコードの末尾の数字はチェックデジットといって、それ以外の桁の数字から計算して出てくる数字なのですが、そのため13桁のISBNコードのチェックデジットは10桁のISBNコードのチェックデジットとは異なっています。わざわざ10桁のコードを計算するのめんどくさいよ!
perl get_amazon_data.pl toaru.tsv > toaru_arasuji.tsv
ともかくこれで、toaru.tsvにあらすじが追加されたtoaru_arasuji.tsvができました。
あらすじテキストをMeCabで処理するために、あらすじテキストをセンテンスごとに分割します。日本語用のセンテンスカッターも探せばどこぞにありそうな気もしますが、まあ適当に作ってみました。スクリプトはsplit_sentence.plです。センテンスごとにISBN, センテンスをタブ区切りで出力します。
perl split_sentence.pl toaru_arasuji.tsv > toaru_sentence.tsv
ここまででMeCabで処理するためのセンテンスデータ、toaru_sentence.tsvが準備できました。MeCabは、Mac OS XならMacPortsを使ってインストールするのが楽ちんでしょう。また、PerlからMeCabを使うためにはText::MeCabをCPANからインストールする必要があります。
split_sentence.plで書き出したファイルから、get_noun_list.plを使ってセンテンスごとにMeCabに渡して名詞のリストを取り出します。このスクリプトでは、連続する名詞は複合名詞として繋ぐ処理を35-68行目でやっていますが……なにぶん、素人のやる事なので。抽出した名詞・複合名詞のリストは、入力ファイルの各行の末尾に追加する形で標準出力されます。
perl get_noun_list.pl toaru_sentence.tsv > toaru_noun.tsv
こうしてセンテンスごとの名詞のリスト、toaru_noun.tsvができたので、この名詞リストを集計してみましょう。まずは単純に集計するだけのバージョンです。スクリプトはcount_noun.plになります。
perl count_noun.pl toaru_noun.tsv > toaru_noun_count.tsv
出力されたtoaru_noun_count.tsvを見てみましょう。下に、最初の10行を表示してあります。
| 学園 都市 | 26 |
| 上条 当麻 | 22 |
| 上条 | 16 |
| インデックス | 16 |
| 物語 | 14 |
| 魔術 | 14 |
| 交差 | 13 |
| 謎 | 11 |
| それ | 10 |
| 御坂 美 琴 | 10 |
このテーブルを見てみると、「上条 当麻」が22、「上条」が16となっています。これは、「とある魔術の禁書目録」既刊24冊のあらすじ中に「上条当麻」が22回、他に何も付かないただの「上条」が16回出てきたことを表しています。単純にカウントするだけならこれでもいいのですが、「上条」には「上条当麻」の22回も追加してやりたいという気もしますね。というわけで、次はこの辺も考慮してカウントしてみましょう。なお、get_noun_list.plでは複合名詞を作る際に名詞の間にスペースを挿入しているため、複合名詞は後からスペースで名詞に分割する事もできるという寸法です。
上に書いたようにカウント方法を変更したスクリプトがcount_noun_with_sub.plになります。実行は先ほどと同じ。
perl count_noun_with_sub.pl toaru_noun.tsv > toaru_noun_count2.tsv
出力されたtoaru_noun_count2.tsvを見てみましょう。先ほどと同じように、下に最初の10行を表示してあります。
| 上条 | 16 | 40 | 上条 当麻(22), 上条 刀 夜(1), 上条 宅(1) |
| 魔術 | 14 | 27 | 魔術 師(9), 魔術 師 ステイル(1), 魔術 組織(1), 魔術 業界 屈指(1), 魔術 側(1) |
| 学園 都市 | 26 | 27 | 学園 都市 最大 級 行事(1) |
| 当麻 | 1 | 23 | 上条 当麻(22) |
| 上条 当麻 | 22 | 22 | |
| インデックス | 16 | 16 | |
| 人 | 1 | 15 | 一 人(6), 二 人(4), 三 人(3), 人 たち(1) |
| 物語 | 14 | 14 | |
| 科学 | 9 | 14 | 一般 科学(2), 反 科学 デモ(1), 科学 サイド(1), 科学 者(1) |
| 御坂 | 1 | 13 | 御坂 美 琴(10), 御坂 妹(2) |
先ほどのテーブルと比べてみましょう。3カラム目が欲しかった数値になります。ただ、ここでひとつ問題があります。「人(ひと)」のカウント結果に「一 人」「二 人」「三 人」が一緒に入っています。こちらの「人」は単位なので一緒に混ぜるのはどうかと思いますが、取ってきたそれぞれの名詞にどんな意味があるのかはリストからはわからないので、ここまでやってきた処理ではこの点はどうしようもありません。それにしてもインデックスさん、空気空気言われるわりにはあらすじだと御坂さんより回数上ですなー。
次に、電撃文庫全体を対象にしてあらすじに使用される名詞の経年変化とか見てみようと思ったのですが、いい加減時間が遅いのでそれはまた次回という事で。
2010年12月14日 火曜日 [長年日記]
_ [Perl] ライトノベルのあらすじを使って遊ぶ - クラスター解析
本日は予定を変更してクラスター解析なぞやってみようと思います。
クラスター解析とは、データのセットの中から似たもの同士をグループにまとめていく手法、と思ってください。
昨日作成した「とある魔術の禁書目録」のあらすじに登場する名詞のリストを使って、「とある魔術の禁書目録」の各巻を似てるもの同士グループ分けしてみます。
テキストデータの解析には、それぞれのテキストデータにどんな単語がどれだけ登場するかを比較するのが常套手段です。そのために、テキストデータごとにどの単語が何回出てきたかという情報をベクトルで表現します。さらに、特定のテキストデータのみに出現する単語は重要で、全体にまんべんなく出てくる単語は重要でないといったように、単語ごとの重要度に応じて重み付けを行います。これには、TF*IDFという方法がよく用いられます。最後にベクトルの大きさがすべて1になるように正規化を行って、各テキストデータのベクトルの向きが近いもの同士をグループにしていくとテキストデータの分類ができるという寸法です。
では、昨日作った「とある魔術の禁書目録」の各巻のあらすじに登場する名詞のリストから各巻のあらすじの文書ベクトルを作ってみます。使うスクリプトはget_matrix_data.plになります。
perl get_matrix_data.pl toaru.tsv toaru_noun_count2.tsv toaru_noun.tsv > toaru_matrix.txt
今回は入力ファイルを3つも使うので、順番を間違えないようにしてください。最初に大元のデータからISBNコードと書名の対応データを、count_noun_with_sub.plの出力ファイルから名詞とその名詞のサブグループである複合名詞のリストの対応データを、get_noun_list.plの出力ファイルからISBNコードとその本のあらすじでの各名詞の出現回数の対応データをそれぞれ取ってきて、各巻ごとにどの名詞が何回出てきたか(カウント方式は改良型)の行列データtoaru_matrix.txtを出力します。このファイルを見てみると、1行目が名詞の見出し欄になっていて、2行目以降に各巻ごとに見出し欄の名詞があらすじに何回登場したかが表示されているのがわかるかと思います。この2行目以降の数字の羅列がそれぞれの本の文書ベクトルというわけです。なお、全体で1回しか出てこない単語は似た者同士のグループ分けの役には立たないので外してあります。
ここまでで文書ベクトルの組が行列の形でできあがったので、これを元にクラスター解析を行います。クラスター解析のような統計処理にはRという統計解析システムがよく使われます。Rについては公式サイトからダウンロードしてインストールしてみてください。Mac OS XではMacPortsでインストールするのもよいでしょう。
正直、Rについては仕事に使うのでクラスタリングのためのスクリプトをひたすらサンプルスクリプトのコピペで作っただけなので、さっぱり分かってません。まあ、その時作ったclustering.Rを使って先ほどの行列データtoaru_matrix.txtのクラスタリングを行い、その結果を樹形図で表示してみましょう。
R --vanilla -q < clustering.R --args toaru_matrix.txt toaru_dendorogram.pdf
Rのスクリプト実行ってわけわからんよな……。ともかくこれで、クラスタリングの結果がtoaru_dendorogram.pdfというファイルに出力されます。PNGに変換したものはこんな感じです。
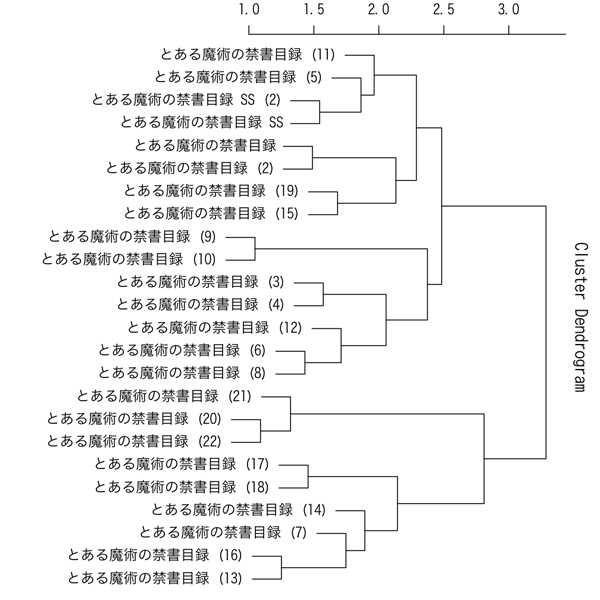
この図、右端を根っこ、左端の書名が書いてある部分を葉とすると、なんとなく木のように見えると思います。そのため、この図は樹形図とかデンドログラムとか言われます。この樹形図では、枝分かれの近い葉同士がお互いによく似ている者同士、枝分かれが遠くなるほど両者の違いが大きくなっていく、というように表現されています。
それでは実際に樹形図を見てみましょう。分かりやすいところでは、6巻・8巻は黒子、9巻・10巻は大覇星祭、13巻・16巻は神の右席、15巻・19巻は学園暗部、17巻・18巻は英国、20-22巻はフィアンマさんという感じで近いもの同士は何となくその理由がわかると思います。また、下側の塊(7・13・14・16・17・18・20・21・22巻)はローマ正教が共通キーワードなんだなーとか、その上の塊(3・4・6・8・9・10・12巻)は御坂さん登場回だなーとか、グループ分けの基準がなんとなく見えるんじゃないかと。
こんな感じで、クラスター解析ってものを使うとテキストデータの分類ができますよ、という紹介でした。
2010年12月16日 木曜日 [長年日記]
_ [Perl] ライトノベルのあらすじを使って遊ぶ - クラスター解析その2
前回の続きです。今回はもう少し大きなデータでやってみましょう。2009年に発売された電撃文庫のあらすじを使ってみます。
grep '^2009' dengeki-bunko.utf-8.tsv > dengeki_2009.tsv perl get_amazon_data.pl dengeki_2009.tsv > dengeki_2009_arasuji.tsv
あらすじテキストの追加されたdengeki_2009_arasuji.tsvができます。現状、アマゾンでは2009年11月発売分にはあらすじが登録されておらず空欄になってしまいますが、手作業で追加するのもめんどくさいので放置します。ちなみに2000-2009年で107冊があらすじ未登録なのですよね……。ただし、クラスタリングする際にあらすじのない本が入っているとそれがひとかたまりになって出てくるので、あらすじのないデータは除いておきましょう。あらすじデータは11番目に入っているので、
perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" if $data[10];}' dengeki_2009_arasuji.tsv > dengeki_2009_arasuji2.tsvあらすじの入っていない本も別に分けておきましょうか。
perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" unless $data[10];}' dengeki_2009_arasuji.tsv > dengeki_2009_arasuji_no_data.tsvdengeki_2009_arasuji2.tsvを使って引き続き、前回と同様に樹形図の出力までやってみましょう。なお、このファイル中の書名は元データのままだと樹形図を書く際に一部の書名が表示されないため、ダッシュ記号はハイフンに置換してあります。また、今回、データが多くなったので、ラベル文字の大きさや線の太さを引数で変更できるようにスクリプトを変更しました。スクリプトは前回とファイル名は同じclustering.Rです。
perl split_sentence.pl dengeki_2009_arasuji2.tsv > dengeki_2009_sentence.tsv perl get_noun_list.pl dengeki_2009_sentence.tsv > dengeki_2009_noun.tsv perl count_noun_with_sub.pl dengeki_2009_noun.tsv > dengeki_2009_noun_count.tsv perl get_matrix_data.pl dengeki_2009_arasuji.tsv dengeki_2009_noun_count.tsv dengeki_2009_noun.tsv > dengeki_2009_matrix.txt R --vanilla -q < clustering.R --args dengeki_2009_matrix.txt dengeki_2009_dendorogram.pdf 3 0.3
clustering.Rの3番目の引数3がラベル文字の大きさ、4番目の引数0.3が線の太さになります。下の図のような樹形図が出力されます。
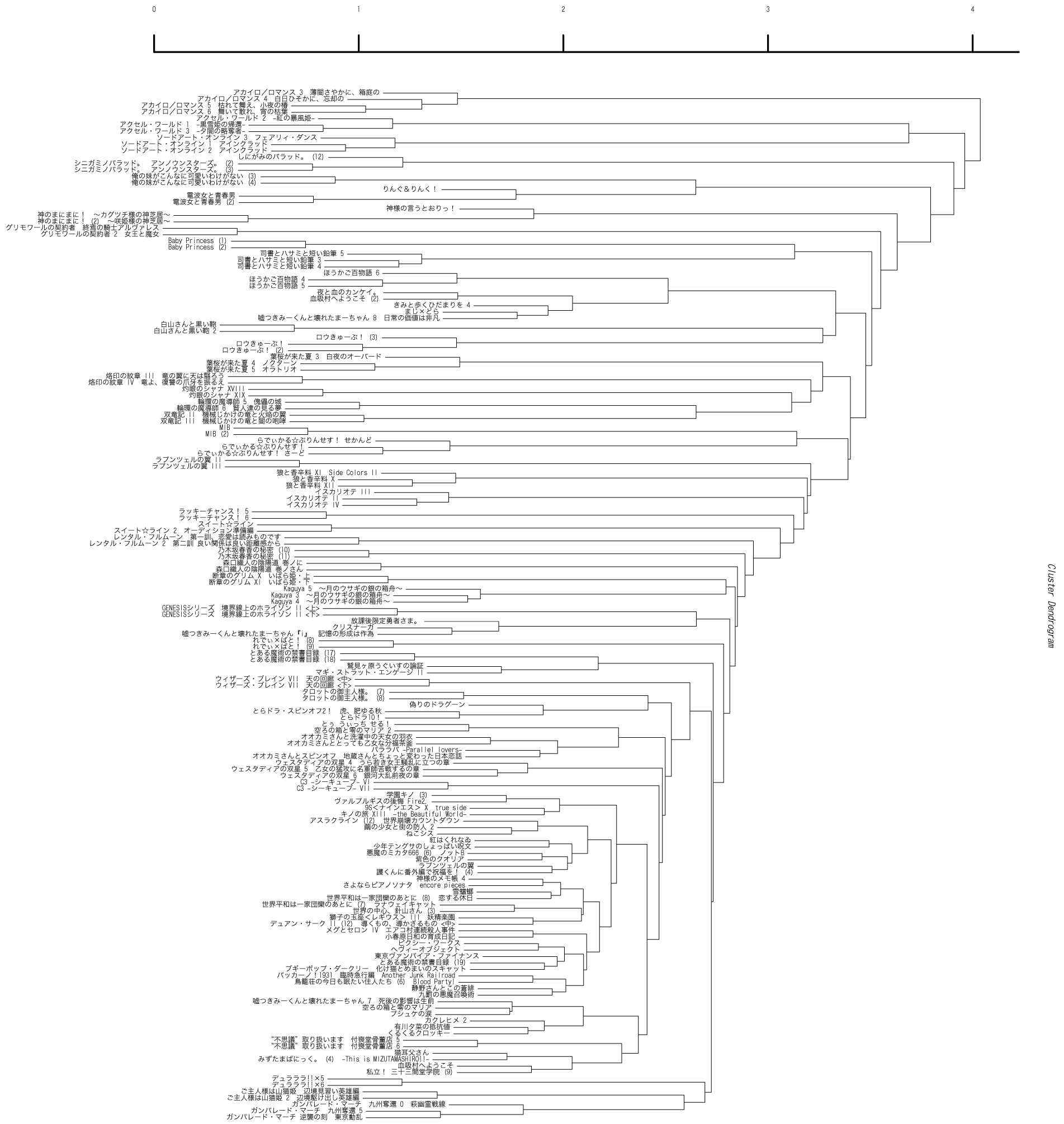
前回の樹形図と比べると、なんだかバランスが変ですね?図をよく見てみると、同じシリーズが末端の方で分岐していて、別シリーズ同士は非常に長い枝で分かれているのがわかります。また、シリーズがいくつかでひとかたまりの枝を作らず、各シリーズの枝が一本ずつ本体から分岐しています。これはどういうことかというと、同じシリーズの本同士は似ているけど、別シリーズの本同士はほとんど比べ様がないほど似ていないということを表しています。これではクラスター解析をする意味がないですね。さてどうしたものか。
前回、TF*IDFという処理について説明しました。特定のテキストデータのみに出現する単語は重要で、全体にまんべんなく出てくる単語は重要でないといったように、単語ごとの重要度に応じて重み付けをする処理でした。そこで、TF*IDFの処理を外して多くの本で共通する単語の重要度を上げてみます。処理としてはclustering.RでのTF*IDFの処理をスキップするだけで、スクリプトはclustering_no_tfidf.Rになります。
R --vanilla -q < clustering_no_tfidf.R --args dengeki_2009_matrix.txt dengeki_2009_dendorogram.pdf
今回は下の図のような樹形図が出力されます。
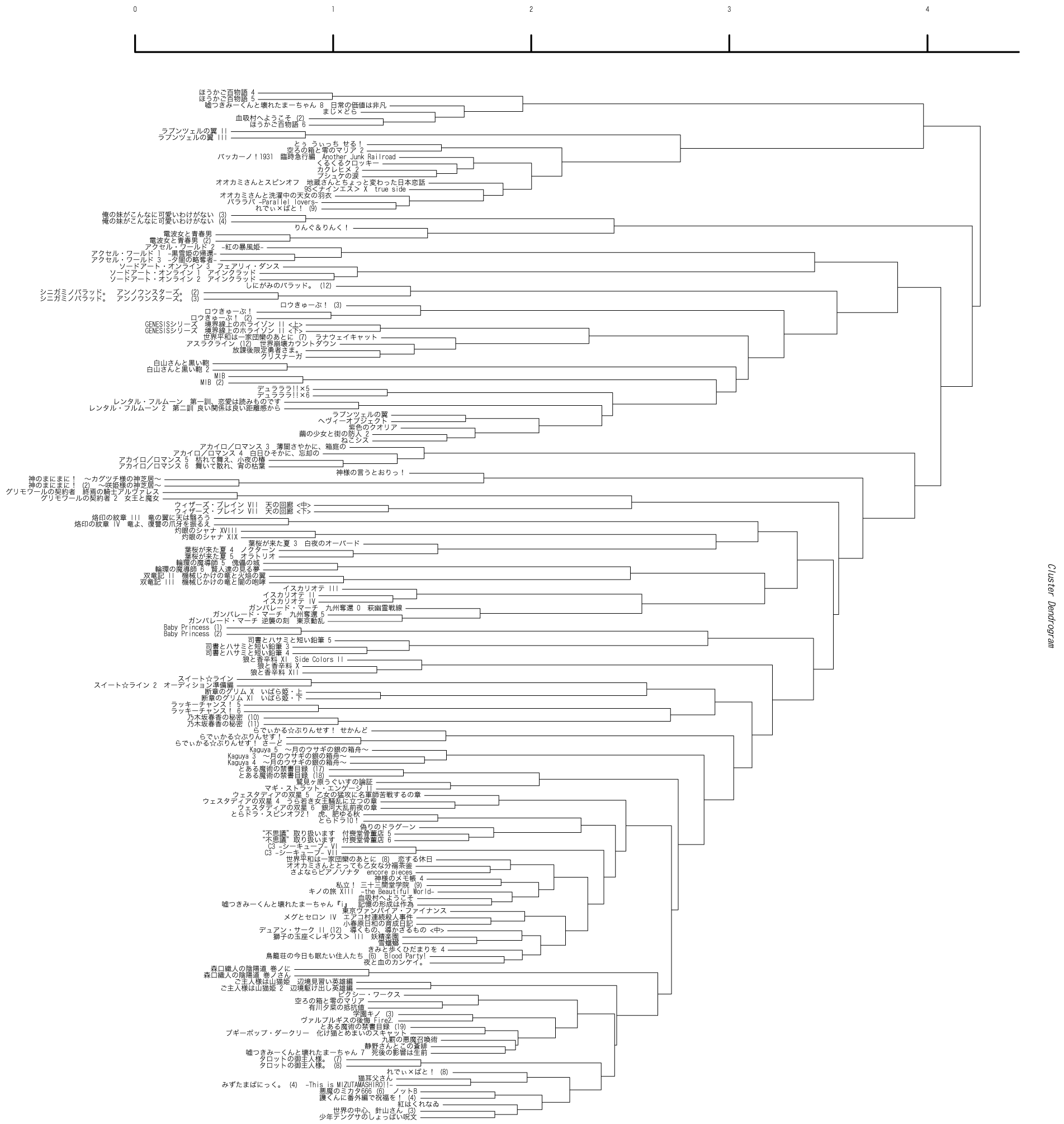
今回は、前回と比べるとかなり固まりができてきましたね。
次に、どっちみちよく似てるもの同士になってしまう同じシリーズの本はひとまとめにしてみましょう。1タイトルあたりのデータ量を増やしてみようという考えです。処理としては、シリーズ名-書名の対応関係を作って、書名単位で集計していたのをシリーズ単位で集計するだけです。というわけで、まずはシリーズ名-書名の対応データを作らなければいけません。基本的に書名の一番最初に出てくるスペースから右を消せばだいたいシリーズ名になりますが、例外もあるので最終的には手作業になります。dengeki_series.tsvです。頑張って2000-2009年のシリーズ名-書名対応データを作りました!このデータ中の書名はdengeki_2009_arasuji2.tsv中の書名と同一でないといけません。
処理に使うデータはこれで全部揃っているので、クラスタリングに使う行列データをシリーズ単位で出力するスクリプトを用意すれば準備完了です。使うスクリプトはget_matrix_by_series.plです。
perl get_matrix_by_series.pl dengeki_2009_arasuji.tsv dengeki_series.tsv dengeki_2009_noun_count.tsv dengeki_2009_noun.tsv 1 > dengeki_2009_series_matrix.txt R --vanilla -q < clustering_no_tfidf.R --args dengeki_2009_series_matrix.txt dengeki_2009_series_dendorogram.pdf
今回、また引数が増えてますね。2番目の引数にシリーズ-書名データが入って、さらに5番目の引数に整数が入ります。この数字は、全体でこの数字以下の使用回数の単語は無視する、という指定に使います。ここでは、これまで通り全体で1回しか出てこない単語は無視しましょう。次のような樹形図が出力されます。

うん、1つめの樹形図と比べると、かなりバランスが良くなった感じですね。これでとりあえずシリーズごとの分類ができたわけですが、ここからさらにこの図のそれぞれの枝の固まりの特徴を、その枝のシリーズでの単語の使用の特徴として調べていくと重要な単語が何なのか見えてくるというわけです。
少し、使われている単語の影響をみてみましょう。下の左側は上の樹形図にサブクラスターごとに色をつけたものです。これに対して右側は、クラスタリングの際にTF*IDF処理を行ったものになります。シリーズ名の色分けは左側と同じ色になるように塗っています。左右で局所的な枝分かれ構造は保持されていますが、全体がばらばらになっていることがわかります。

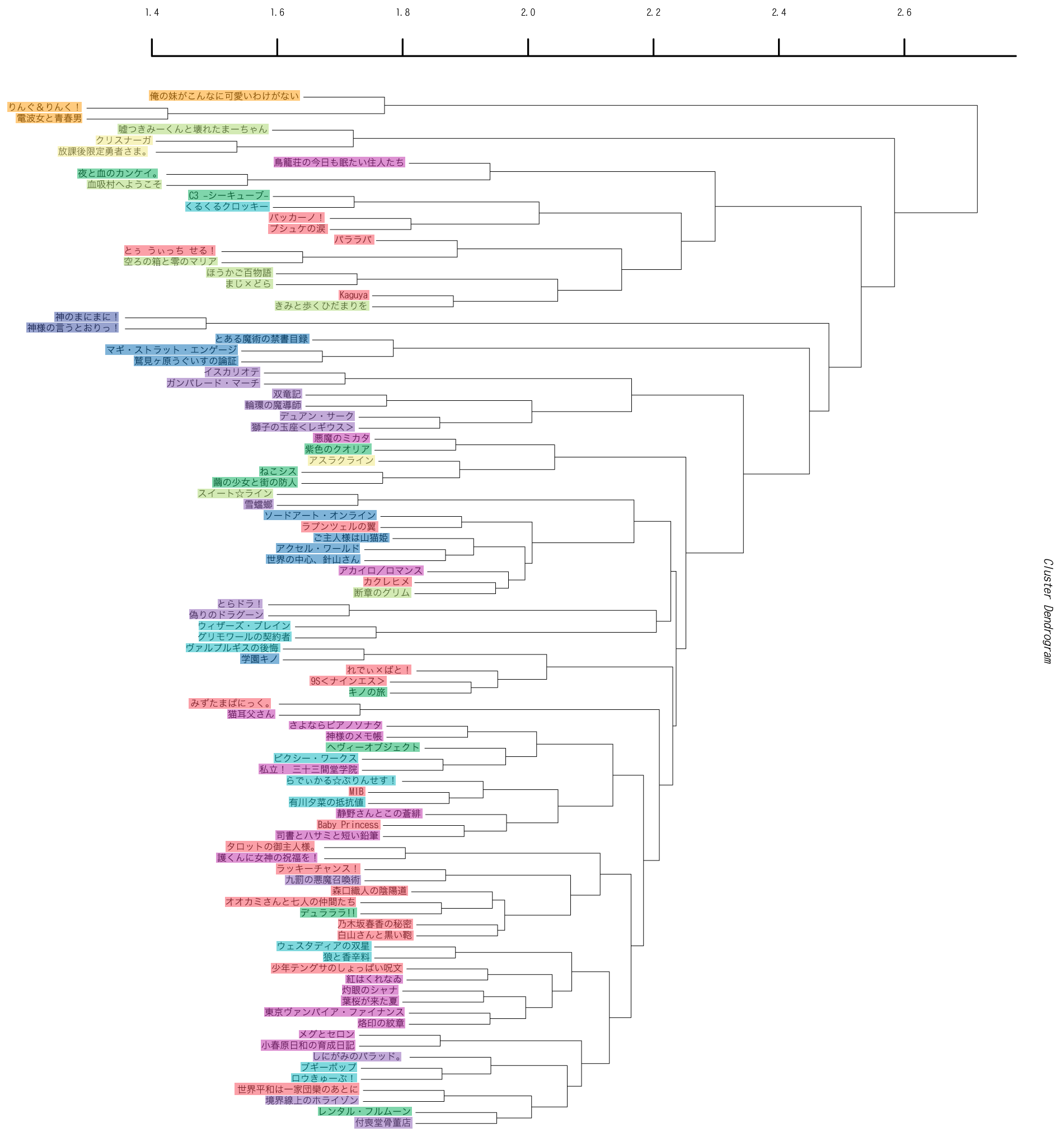
TF*IDF処理を行うと、広い範囲で出現する単語の重要度が下がります。逆に言えば、TF*IDF処理を行っていない左側の樹形図では、広い範囲で出現する単語の重要度が上がっている事になります。つまり、左側の樹形図で右側には出てこないクラスターを作らせているのは、「彼女」とか「少女」といった非常によく出てくる単語ということになります。
2010年12月18日 土曜日 [長年日記]
_ [Perl] ライトノベルのあらすじを使って遊ぶ - サブクラスターの特徴を調べる
昨日作った、2009年発売の電撃文庫のあらすじから抽出した名詞によるシリーズの分類がどのような特徴によるものかを見てみましょう。
Rを使ったクラスター解析では、単に樹形図を出力するだけではなく、クラスター解析の結果をいくつのサブクラスターに分割するか設定し、各サブクラスターには何が含まれるか、といったことももちろん出力できます。そのように書き換えたスクリプトはclustering_no_tfidf.Rになります。
R --vanilla -q < clustering_no_tfidf.R --args dengeki_2009_series_matrix.txt dengeki_2009_series_dendorogram.pdf 4 0.3 10 subcluster.txt result.txt
今回は引数が3個増えて7個になっています。5番目の引数はクラスター解析の結果をいくつのサブクラスターに分割するかの指定、6番目の引数はクラスター解析にかけた各要素がどのサブクラスターに含まれるかの結果の出力ファイル、7番目の引数は樹形図の元になっている数値データの出力ファイルです。最後の出力ファイルはとりあえずは必要ないのですが、まあ一応出しておきます。上のコマンドでは、クラスタリングの結果を10個に分割するよう指定しています。実際にどこで分割されるかというと、下の図の赤のラインになります。なお、樹形図自体は昨日のものと同じですが、都合により色の塗り分けが若干変わっています。
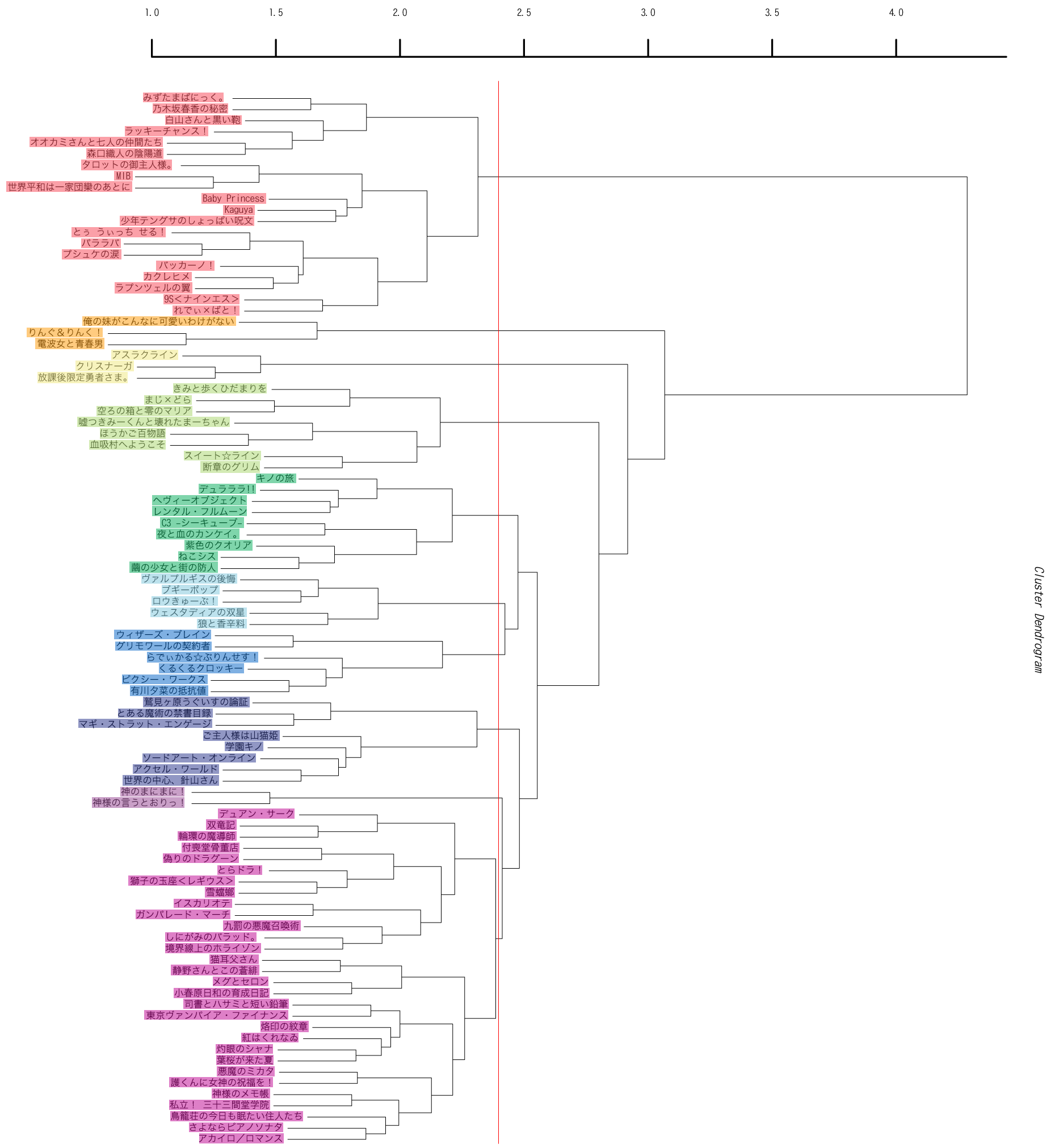
subcluster.txtにはdengeki_2009_series_matrix.txtの1列目のシリーズ名が上から順に1〜10のどのサブクラスターに入るかが出力されます。
ここまで来れば、後は各サブクラスターごとにdengeki_2009_series_matrix.txtからどの単語が何回出てきたかを集計してやれば、各サブクラスターで使用された単語の特徴がわかるはずです。というわけで、count_subcluster_word.plで集計してみましょう。
perl count_subcluster_word.pl subcluster.txt dengeki_2009_series_matrix.txt > dengeki_2009_subcluster_word_count.txt
出力されたdengeki_2009_subcluster_word_count.txtには、1列目に単語、2列めにサブクラスター1での使用回数、3列目に2列目の数値をサブクラスター1に含まれるシリーズ数で割った数値...というようにRの実行時に指定したサブクラスターの数だけ数値が出力されています。サブクラスターの何番は樹形図のどこの枝かというのは行列データ(dengeki_2009_series_matrix.txt)の1列目のラベルとsubcluster.txtと樹形図を比較しないといけないのでちとめんどくさいのですが、とりあえず大事そうな部分を抜き出した結果が下のテーブルになります。※見直してみるとどうにもデータのピックアップがいまいちだったので修正しました(2010/12/18 16:20)。
| 単語 | 合計 | 1(赤) | 2(緑) | 3(黄緑) | 4(青) | 5(藍) | 6(赤紫) | 7(橙) | 8(黄) | 9(水色) | 10(紫) | ||||||||||
| 人 | 141 | 80 | 4.0 | 4 | 0.4 | 4 | 0.5 | 8 | 1.3 | 11 | 1.4 | 20 | 0.7 | 2 | 0.7 | 0 | 0.0 | 4 | 0.8 | 8 | 4.0 |
| 二 | 52 | 29 | 1.5 | 2 | 0.2 | 4 | 0.5 | 2 | 0.3 | 5 | 0.6 | 8 | 0.3 | 0 | 0.0 | 1 | 0.3 | 1 | 0.2 | 0 | 0.0 |
| 二 人 | 32 | 23 | 1.2 | 0 | 0.0 | 1 | 0.1 | 1 | 0.2 | 3 | 0.4 | 4 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 人間 | 26 | 0 | 0.0 | 17 | 1.9 | 3 | 0.4 | 0 | 0.0 | 0 | 0.0 | 5 | 0.2 | 0 | 0.0 | 1 | 0.3 | 0 | 0.0 | 0 | 0.0 |
| 少女 | 63 | 15 | 0.8 | 15 | 1.7 | 2 | 0.3 | 4 | 0.7 | 6 | 0.8 | 10 | 0.3 | 3 | 1.0 | 1 | 0.3 | 7 | 1.4 | 0 | 0.0 |
| 僕 | 21 | 1 | 0.1 | 0 | 0.0 | 19 | 2.4 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 魔法 | 17 | 1 | 0.1 | 0 | 0.0 | 1 | 0.1 | 15 | 2.5 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 彼女 | 74 | 25 | 1.3 | 2 | 0.2 | 12 | 1.5 | 12 | 2.0 | 7 | 0.9 | 10 | 0.3 | 1 | 0.3 | 1 | 0.3 | 4 | 0.8 | 0 | 0.0 |
| 魔法 書 | 11 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 11 | 1.8 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 秘密 | 21 | 5 | 0.3 | 0 | 0.0 | 0 | 0.0 | 8 | 1.3 | 0 | 0.0 | 6 | 0.2 | 1 | 0.3 | 1 | 0.3 | 0 | 0.0 | 0 | 0.0 |
| 彼 | 28 | 4 | 0.2 | 1 | 0.1 | 2 | 0.3 | 1 | 0.2 | 14 | 1.8 | 6 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 姫 | 18 | 3 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 12 | 1.5 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.5 |
| 魔術 | 10 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 10 | 1.3 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 謎 | 27 | 5 | 0.3 | 3 | 0.3 | 3 | 0.4 | 2 | 0.3 | 9 | 1.1 | 5 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 俺 | 23 | 3 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 19 | 6.3 | 0 | 0.0 | 1 | 0.2 | 0 | 0.0 |
| さん | 49 | 25 | 1.3 | 1 | 0.1 | 12 | 1.5 | 0 | 0.0 | 2 | 0.3 | 0 | 0.0 | 8 | 2.7 | 0 | 0.0 | 1 | 0.2 | 0 | 0.0 |
| 小説 | 16 | 2 | 0.1 | 1 | 0.1 | 2 | 0.3 | 0 | 0.0 | 3 | 0.4 | 1 | 0.0 | 5 | 1.7 | 0 | 0.0 | 0 | 0.0 | 2 | 1.0 |
| 青春 | 7 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.2 | 1 | 0.1 | 0 | 0.0 | 5 | 1.7 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 女 | 21 | 2 | 0.1 | 6 | 0.7 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 3 | 0.1 | 4 | 1.3 | 1 | 0.3 | 4 | 0.8 | 0 | 0.0 |
| 相談 | 6 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 1.3 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 布団 | 4 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 1.3 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 世界 | 38 | 4 | 0.2 | 5 | 0.6 | 1 | 0.1 | 4 | 0.7 | 4 | 0.5 | 7 | 0.2 | 0 | 0.0 | 12 | 4.0 | 1 | 0.2 | 0 | 0.0 |
| ぼく | 9 | 0 | 0.0 | 0 | 0.0 | 3 | 0.4 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 5 | 1.7 | 0 | 0.0 | 0 | 0.0 |
| たち | 77 | 21 | 1.1 | 2 | 0.2 | 10 | 1.3 | 5 | 0.8 | 6 | 0.8 | 14 | 0.5 | 0 | 0.0 | 2 | 0.7 | 17 | 3.4 | 0 | 0.0 |
| 王国 | 9 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 7 | 1.4 | 0 | 0.0 |
| それ | 39 | 10 | 0.5 | 3 | 0.3 | 3 | 0.4 | 2 | 0.3 | 2 | 0.3 | 11 | 0.4 | 0 | 0.0 | 0 | 0.0 | 7 | 1.4 | 1 | 0.5 |
| ー | 13 | 1 | 0.1 | 0 | 0.0 | 2 | 0.3 | 1 | 0.2 | 0 | 0.0 | 1 | 0.0 | 2 | 0.7 | 0 | 0.0 | 6 | 1.2 | 0 | 0.0 |
| 狼 | 6 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 6 | 1.2 | 0 | 0.0 |
| 神様 | 12 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 11 | 5.5 |
| ヘッポコ | 5 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 5 | 2.5 |
| 神 | 8 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 2.0 |
| 様 | 6 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 2.0 |
こうして見ると、なかなか奇麗に分かれてますな。赤は「二人」クラスター、オレンジは「俺」クラスター、黄は「世界・ぼく」クラスター、黄緑は「僕」クラスター、緑は「人間」クラスター、水色はちょっと微妙ですが「○○たち・王国」クラスター、青は「魔法・秘密」クラスター、藍は「彼・姫・魔術・謎」クラスター、紫は「神様」クラスター、赤紫はそのどれでもないものって感じの分類になっているようです。このクラスタリングではTF*IDFを行っていないので、ここに出てくるような使用頻度の大きな単語がそのままクラスターの形成に影響を与えているわけです。TF*IDFを行ってクラスタリングした場合は、補正後の数値を算出しないと実際の影響は見られない事に注意してください。また、実際にはここに出した以外の様々な単語の影響があるわけですが、ここでは思いっきり単純化してみました。
次は、ゼロ年代の本全部を対象にしてやってみましょうかね?
2010年12月23日 木曜日 [長年日記]
_ [Perl] ゼロ年代の電撃文庫をあらすじに出てくる名詞を使って分類してみる
今回のお話は、12/13、12/14、12/16、12/18の続きになっています。そんなわけで、今度は2000年から2009年までの電撃文庫をあらすじに出てくる名詞で分類してみる。
まず、2000-2009年の電撃文庫でアマゾンにあらすじが登録されていなかった本が107冊あったので、アスキー・メディアワークスの雑誌・書籍検索からデータを取ってくる。ここの書籍検索はISBNで検索した後さらに独自設定のキーで個別のページに移動しないとデータに辿り着けないので、アマゾンよりはちょっと面倒。取ってくるスクリプトはget_mw_data.plになります。アマゾンから取ってくるスクリプトと基本的に同じなので、12/13の記事を読んでください。まずはアマゾンから取ってきて、12/16の記事にあるようにあらすじの取れたデータと取れなかったデータに分割して、あらすじの取れなかったデータのファイルを入力ファイルとしてメディアワークスからデータを取ってきます。アマゾンから取ってきた後で使うことを前提に作ってあるので、ラノベの杜のファイルにそのまま使うとあらすじの前にタブが入らないことに注意。
$ grep '^200' dengeki-bunko.utf-8.tsv | grep -v '^2009' > dengeki_2000-2008.tsv
$ perl get_amazon_data.pl dengeki_2000-2008.tsv > dengeki_2000-2008_arasuji.tsv
$ cat dengeki_2000-2008_arasuji.tsv dengeki_2009_arasuji.tsv > dengeki_2000-2009_arasuji.tsv
$ perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" if $data[10];}' dengeki_2000-2009_arasuji.tsv > dengeki_2000-2009_arasuji2.tsv
$ perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" unless $data[10];}' dengeki_2000-2009_arasuji.tsv > dengeki_2000-2009_arasuji_no_data.tsv
$ perl get_mw_data.pl dengeki_2000-2009_arasuji_no_data.tsv > dengeki_2000-2009_arasuji_add.tsv
$ perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" if $data[10];}' dengeki_2000-2009_arasuji_add.tsv > dengeki_2000-2009_arasuji_add2.tsv
$ perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" unless $data[10];}' dengeki_2000-2009_arasuji_add.tsv > dengeki_2000-2009_arasuji_no_data2.tsv
$ cat dengeki_2000-2009_arasuji2.tsv dengeki_2000-2009_arasuji_add2.tsv > dengeki_2000-2009_arasuji3.tsv
……さすがに長くてわけわからなくなりそうなので、頭にコマンドプロンプト付けてみた。これで、アマゾンかメディアワークスであらすじの取れたdengeki_2000-2009_arasuji3.tsvとあらすじの取れなかったdengeki_2000-2009_arasuji_no_data2.tsvができます。ちなみにメディアワークスで探しても37冊についてはあらすじが取れませんでした。絶版になるとデータ自体が消されちゃうみたいですねー。
この後は名詞リストを取り出すとこまでは前回と同じ。
$ perl split_sentence.pl dengeki_2000-2009_arasuji3.tsv > dengeki_2000-2009_sentence.tsv $ perl get_noun_list.pl dengeki_2000-2009_sentence.tsv > dengeki_2000-2009_noun.tsv $ perl count_noun_with_sub.pl dengeki_2000-2009_noun.tsv > dengeki_2000-2009_noun_count.tsv
クラスタリングに使う行列データを出力する時に、前回は全体で1回しか出てこない単語は単独のシリーズでしか出てこないからということでカットしましたが、今回はもっと積極的に単一のシリーズにしか出てこない単語はすべてカットすることにします。そしてもうひとつ、シリーズ中のそれぞれの本が発売された年をキーワードとしてカウントすることにします。例えばあるシリーズで2008年に2冊、2009年に1冊本が出たとすると、そのシリーズの単語リストに2008年が2、2009年が1と入るわけです。まあ、そもそも当初のネタが「ライトノベルのあらすじからトレンドを知ることができるか」だったので、ちょっとはその努力をしてみようってことで。スクリプトはget_matrix_by_series_year3.plになります。
$ perl get_matrix_by_series_year3.pl dengeki_2000-2009_arasuji3.tsv dengeki_series.tsv dengeki_2000-2009_noun_count.tsv dengeki_2000-2009_noun.tsv 1 > dengeki_2000-2009_series_matrix.txt $ R --vanilla -q < clustering_no_tfidf.R --args dengeki_2000-2009_series_matrix.txt dengeki_2000-2009_series_dendrogram.pdf 1 0.1 10 subcluster.txt result.txt $ perl count_subcluster_word.pl subcluster.txt dengeki_2000-2009_series_matrix.txt > dengeki_2000-2009_subcluster_word_count.txt
下のような樹形図になりました。PDF版はこちら。……データ多すぎて見難いなーこりゃ。サブクラスターとシリーズ名の対応はsubcluster_list.txt、サブクラスターごとの単語のカウント結果はdengeki_2000-2009_series_subcluster_word_count.txtになります。

大まかに見ると、赤, 橙, 黄+黄緑+緑+水色, 青+藍+紫+赤紫の4グループになっています。
これがサブクラスターごとの単語カウントの主立ったところを抜き出したもの。……いい加減疲れたので色付けは勘弁な。起きたら気力が戻ったので塗ってやった!
| 単語 | 5(赤) | 7(橙) | 9(黄) | 6(黄緑) | 2(緑) | 3(水色) | 10(青) | 1(藍) | 8(紫) | 4(赤紫) | 合計 | ||||||||||
| 人 | 332 | 4.9 | 14 | 0.9 | 45 | 2.1 | 9 | 0.6 | 97 | 1.6 | 120 | 0.9 | 13 | 1.1 | 6 | 1.1 | 14 | 0.7 | 119 | 1.3 | 769 |
| 少女 | 103 | 1.5 | 14 | 0.9 | 19 | 0.9 | 3 | 0.2 | 67 | 1.1 | 41 | 0.3 | 7 | 0.6 | 2 | 0.3 | 84 | 4.2 | 55 | 0.6 | 395 |
| 彼女 | 74 | 1.1 | 26 | 1.6 | 14 | 0.7 | 5 | 0.4 | 31 | 0.5 | 44 | 0.3 | 27 | 2.3 | 3 | 0.5 | 12 | 0.6 | 145 | 1.6 | 381 |
| 世界 | 61 | 0.9 | 126 | 7.9 | 10 | 0.5 | 2 | 0.1 | 26 | 0.4 | 86 | 0.6 | 8 | 0.7 | 0 | 0.0 | 8 | 0.4 | 35 | 0.4 | 362 |
| 二 | 139 | 2.0 | 7 | 0.4 | 18 | 0.9 | 6 | 0.4 | 32 | 0.5 | 50 | 0.4 | 4 | 0.3 | 0 | 0.0 | 7 | 0.4 | 78 | 0.8 | 341 |
| たち | 63 | 0.9 | 13 | 0.8 | 10 | 0.5 | 3 | 0.2 | 30 | 0.5 | 83 | 0.6 | 11 | 0.9 | 1 | 0.2 | 11 | 0.6 | 91 | 1.0 | 316 |
| それ | 63 | 0.9 | 13 | 0.8 | 19 | 0.9 | 6 | 0.4 | 54 | 0.9 | 54 | 0.4 | 11 | 0.9 | 0 | 0.0 | 14 | 0.7 | 79 | 0.8 | 313 |
| 一 | 109 | 1.6 | 9 | 0.6 | 16 | 0.8 | 1 | 0.1 | 29 | 0.5 | 46 | 0.3 | 7 | 0.6 | 2 | 0.3 | 3 | 0.2 | 55 | 0.6 | 277 |
| 二 人 | 124 | 1.8 | 4 | 0.3 | 15 | 0.7 | 4 | 0.3 | 17 | 0.3 | 23 | 0.2 | 2 | 0.2 | 0 | 0.0 | 6 | 0.3 | 41 | 0.4 | 236 |
| 謎 | 46 | 0.7 | 17 | 1.1 | 14 | 0.7 | 5 | 0.4 | 22 | 0.4 | 77 | 0.6 | 8 | 0.7 | 1 | 0.2 | 2 | 0.1 | 33 | 0.4 | 225 |
| 前 | 55 | 0.8 | 9 | 0.6 | 19 | 0.9 | 4 | 0.3 | 26 | 0.4 | 53 | 0.4 | 6 | 0.5 | 1 | 0.2 | 6 | 0.3 | 40 | 0.4 | 219 |
| 彼 | 44 | 0.6 | 7 | 0.4 | 9 | 0.4 | 0 | 0.0 | 57 | 0.9 | 46 | 0.3 | 3 | 0.3 | 0 | 0.0 | 3 | 0.2 | 41 | 0.4 | 210 |
| 登場 | 39 | 0.6 | 4 | 0.3 | 17 | 0.8 | 2 | 0.1 | 27 | 0.4 | 77 | 0.6 | 11 | 0.9 | 2 | 0.3 | 2 | 0.1 | 29 | 0.3 | 210 |
| 事件 | 46 | 0.7 | 3 | 0.2 | 8 | 0.4 | 30 | 2.1 | 27 | 0.4 | 44 | 0.3 | 11 | 0.9 | 0 | 0.0 | 4 | 0.2 | 34 | 0.4 | 207 |
| シリーズ | 58 | 0.9 | 9 | 0.6 | 26 | 1.2 | 2 | 0.1 | 10 | 0.2 | 69 | 0.5 | 6 | 0.5 | 1 | 0.2 | 3 | 0.2 | 17 | 0.2 | 201 |
| 物語 | 23 | 0.3 | 10 | 0.6 | 5 | 0.2 | 2 | 0.1 | 55 | 0.9 | 32 | 0.2 | 6 | 0.5 | 0 | 0.0 | 17 | 0.9 | 29 | 0.3 | 179 |
| そこ | 48 | 0.7 | 6 | 0.4 | 13 | 0.6 | 1 | 0.1 | 24 | 0.4 | 40 | 0.3 | 9 | 0.8 | 0 | 0.0 | 7 | 0.4 | 20 | 0.2 | 168 |
| 彼ら | 25 | 0.4 | 10 | 0.6 | 22 | 1.0 | 1 | 0.1 | 33 | 0.5 | 38 | 0.3 | 1 | 0.1 | 0 | 0.0 | 8 | 0.4 | 13 | 0.1 | 151 |
| 電撃 | 21 | 0.3 | 3 | 0.2 | 53 | 2.5 | 0 | 0.0 | 17 | 0.3 | 29 | 0.2 | 6 | 0.5 | 1 | 0.2 | 2 | 0.1 | 17 | 0.2 | 149 |
| 僕 | 7 | 0.1 | 1 | 0.1 | 2 | 0.1 | 4 | 0.3 | 3 | 0.0 | 8 | 0.1 | 92 | 7.7 | 0 | 0.0 | 5 | 0.3 | 27 | 0.3 | 149 |
| 力 | 37 | 0.5 | 5 | 0.3 | 19 | 0.9 | 7 | 0.5 | 16 | 0.3 | 26 | 0.2 | 1 | 0.1 | 0 | 0.0 | 2 | 0.1 | 26 | 0.3 | 139 |
| 一 人 | 79 | 1.2 | 3 | 0.2 | 7 | 0.3 | 0 | 0.0 | 10 | 0.2 | 12 | 0.1 | 3 | 0.3 | 2 | 0.3 | 1 | 0.1 | 17 | 0.2 | 134 |
| 小説 | 15 | 0.2 | 2 | 0.1 | 49 | 2.3 | 0 | 0.0 | 9 | 0.1 | 35 | 0.3 | 6 | 0.5 | 3 | 0.5 | 1 | 0.1 | 5 | 0.1 | 125 |
| ゲーム | 12 | 0.2 | 0 | 0.0 | 27 | 1.3 | 1 | 0.1 | 11 | 0.2 | 47 | 0.3 | 2 | 0.2 | 0 | 0.0 | 1 | 0.1 | 12 | 0.1 | 113 |
| 大賞 | 14 | 0.2 | 3 | 0.2 | 55 | 2.6 | 0 | 0.0 | 11 | 0.2 | 6 | 0.0 | 12 | 1.0 | 1 | 0.2 | 1 | 0.1 | 5 | 0.1 | 108 |
| 受賞 | 12 | 0.2 | 3 | 0.2 | 48 | 2.3 | 0 | 0.0 | 10 | 0.2 | 7 | 0.1 | 6 | 0.5 | 1 | 0.2 | 1 | 0.1 | 3 | 0.0 | 91 |
| 神 | 10 | 0.1 | 6 | 0.4 | 5 | 0.2 | 1 | 0.1 | 50 | 0.8 | 7 | 0.1 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 5 | 0.1 | 85 |
| 過去 | 11 | 0.2 | 12 | 0.8 | 7 | 0.3 | 2 | 0.1 | 15 | 0.2 | 20 | 0.1 | 4 | 0.3 | 0 | 0.0 | 2 | 0.1 | 10 | 0.1 | 83 |
| 学校 | 14 | 0.2 | 3 | 0.2 | 2 | 0.1 | 1 | 0.1 | 11 | 0.2 | 12 | 0.1 | 11 | 0.9 | 0 | 0.0 | 3 | 0.2 | 24 | 0.3 | 81 |
| 俺 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 3 | 0.0 | 7 | 0.1 | 0 | 0.0 | 39 | 6.5 | 0 | 0.0 | 28 | 0.3 | 78 |
| 妹 | 8 | 0.1 | 2 | 0.1 | 1 | 0.0 | 0 | 0.0 | 11 | 0.2 | 16 | 0.1 | 6 | 0.5 | 8 | 1.3 | 1 | 0.1 | 11 | 0.1 | 64 |
| 危機 | 8 | 0.1 | 16 | 1.0 | 2 | 0.1 | 0 | 0.0 | 7 | 0.1 | 19 | 0.1 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 9 | 0.1 | 62 |
| 第 4 | 20 | 0.3 | 1 | 0.1 | 16 | 0.8 | 0 | 0.0 | 4 | 0.1 | 8 | 0.1 | 3 | 0.3 | 0 | 0.0 | 0 | 0.0 | 9 | 0.1 | 61 |
| 受賞 作 | 9 | 0.1 | 3 | 0.2 | 26 | 1.2 | 0 | 0.0 | 3 | 0.0 | 3 | 0.0 | 5 | 0.4 | 1 | 0.2 | 0 | 0.0 | 2 | 0.0 | 52 |
| 金賞 | 9 | 0.1 | 2 | 0.1 | 22 | 1.0 | 0 | 0.0 | 2 | 0.0 | 7 | 0.1 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 43 |
| G | 0 | 0.0 | 41 | 2.6 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 43 |
| ぼく | 15 | 0.2 | 17 | 1.1 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 4 | 0.3 | 0 | 0.0 | 0 | 0.0 | 5 | 0.1 | 42 |
| 異 | 9 | 0.1 | 13 | 0.8 | 5 | 0.2 | 0 | 0.0 | 0 | 0.0 | 9 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 6 | 0.1 | 42 |
| 殺人 | 4 | 0.1 | 0 | 0.0 | 1 | 0.0 | 13 | 0.9 | 11 | 0.2 | 0 | 0.0 | 3 | 0.3 | 0 | 0.0 | 0 | 0.0 | 3 | 0.0 | 35 |
| ー | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 3 | 0.0 | 9 | 0.8 | 0 | 0.0 | 0 | 0.0 | 21 | 0.2 | 35 |
| 死神 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 22 | 1.1 | 7 | 0.1 | 32 |
| 座敷 童 | 4 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 14 | 1.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 18 |
| 異 世界 | 1 | 0.0 | 12 | 0.8 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 2 | 0.0 | 18 |
| 殺人 事件 | 2 | 0.0 | 0 | 0.0 | 0 | 0.0 | 11 | 0.8 | 2 | 0.0 | 0 | 0.0 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 17 |
| 僕ら | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 11 | 0.9 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 12 |
こちらは単語リストに追加した発売年を抜き出したもの。
| 発売年 | 赤 | 橙 | 黄 | 黄緑 | 緑 | 水色 | 青 | 藍 | 紫 | 赤紫 | 合計 |
| 2000年 | 10 | 1 | 14 | 0 | 9 | 54 | 1 | 1 | 0 | 7 | 97 |
| 2001年 | 19 | 2 | 10 | 4 | 8 | 58 | 0 | 0 | 3 | 9 | 113 |
| 2002年 | 31 | 4 | 8 | 0 | 15 | 50 | 0 | 0 | 2 | 3 | 113 |
| 2003年 | 36 | 8 | 9 | 1 | 18 | 40 | 4 | 0 | 6 | 9 | 131 |
| 2004年 | 45 | 4 | 7 | 1 | 28 | 36 | 3 | 0 | 6 | 12 | 142 |
| 2005年 | 46 | 10 | 4 | 5 | 32 | 29 | 7 | 0 | 4 | 23 | 160 |
| 2006年 | 35 | 4 | 12 | 5 | 23 | 33 | 6 | 0 | 8 | 41 | 167 |
| 2007年 | 35 | 10 | 7 | 0 | 27 | 31 | 5 | 2 | 4 | 41 | 162 |
| 2008年 | 21 | 12 | 12 | 1 | 19 | 18 | 8 | 2 | 5 | 71 | 169 |
| 2009年 | 19 | 6 | 9 | 0 | 20 | 26 | 10 | 6 | 6 | 72 | 174 |
| 合計 | 297 | 61 | 92 | 17 | 199 | 375 | 44 | 11 | 44 | 288 | 1428 |
| シリーズ数 | 68 | 16 | 21 | 14 | 62 | 136 | 12 | 6 | 20 | 93 | 449 |
| シリーズ平均冊数 | 4.4 | 3.8 | 4.4 | 1.2 | 3.2 | 2.8 | 3.7 | 1.8 | 2.2 | 3.1 | 3.2 |
以上の結果から、超適当に各サブクラスターの特徴を見ていきます。
青グループの支配的単語は「僕」。全149回中92回がこのグループに出てきます。また、青グループの12シリーズ44冊のうち10冊が2009年、8冊が2008年に出ており、2000-2004年の5年間では8冊しか出ていません。
藍グループの支配的単語は「俺」。全78回中39回がこのグループに出てきます。また、藍グループの6シリーズ11冊のうち10冊は2007-2009年に出ています。なお、「俺」の残り39回のうち28回は赤紫グループに出てきます。青グループと藍グループを合わせて、一人称なあらすじは2007年辺りから多くなってきたってことなんだろうか。
紫グループで最も多い単語は「少女」ですが、実のところこれは他のグループにもよく出てきます。次に多いのは「死神」で全32回中22回がこのグループに出てきます。発売年は2000年の0冊以外、わりと均等に散らばっています。なお、「死神」の残り10回のうち7回は赤紫グループに出てきます。
赤紫グループで多い単語は「彼女」「人」。「彼女」は全381回中145回なのでわりと多めに集まっている感じですが、「人」は全769回中119回なのでそんなでもありません。ぶっちゃけこのグループは単語的に特徴がないので電撃文庫的に普通な単語グループになっていますが、青・藍グループに引っ張られて2005年以降、特に2008年・2009年のものが集まっています。……いや待て違うな。クラスタリングの手順からいくと、赤紫のグループが束ね終わった後で、そこに似てるものとして藍とか青のグループが束ねられるんだから、順番が逆か。ともかく、288冊中143冊が2008年・2009年の2年間に集中しています。要するに、電撃文庫のあらすじ的に普通な新しめの本のグループですかね。
水色グループは特徴がないのが特徴。どこにも入らなかったものがここに集まってる感じです。「少女」とか「彼女」といった単語が抜きん出ているといった特徴すらありません。発売年としては新しいものは赤紫グループに入っているので、それ以外がここに来ています。
緑グループは電撃文庫全体の平均がここに集まったと言わんばかりのグループです。全体で1位・2位の「人」「少女」はここでも1位・2位になっています。発売年としては全199冊中110冊が2004-2007年になっています。
黄緑グループで最も多い単語は「事件」。特に「殺人事件」は全17回中11回がこのグループです。また、全体で出現回数の多い単語はこのグループにはほとんど出てこないのも特徴です。発売年は全14シリーズ・17冊中14冊が2001年, 2005年, 2006年に出ています。
黄色グループは「大賞」「電撃」「小説」「受賞」が上位4単語になります。……まあ要するに、そういうグループがここに集まっているわけですな。その手の単語の出てくる本のうち半分はこのグループに入っているようです。つまり、受賞以外に特徴的な単語のないものがここに来ていることになりますか。発売年はわりと均等に散らばっている感じ。
橙グループの支配的単語は「世界」。全362回中126回がこのグループに出てきます。「異世界」も多いですねー。全18回中12回がこのグループです。あとは、「ぼく」が全42回中17回がこのグループ、15回が赤グループに出てきます。年ごとの冊数は、増えたり減ったりを繰り返しながらだんだんと増えていっているようです。
赤グループの支配的単語は「二人」。全236回中124回がこのグループに出てきます。また、「一人」も全134回中79回がこのグループです。他に目を引くのは、「悪魔」の全71回中47回かな。
グループごとのシリーズの平均継続冊数を見てみると、赤・黄が最も多くて4.4冊、続いて橙の3.8冊、青の3.7冊となっています。無個性の集まりの水色は2.8冊と低めです。
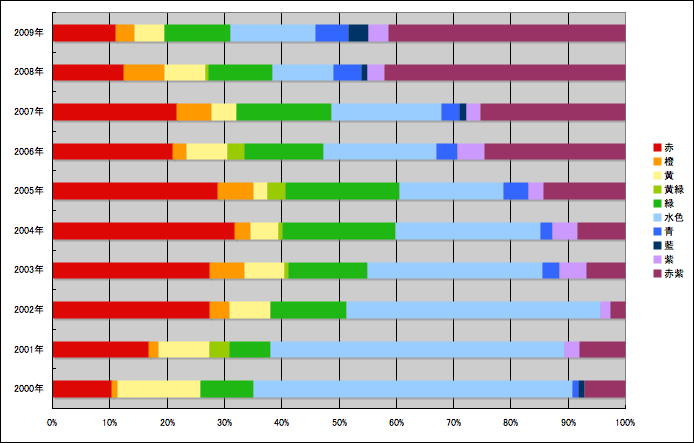
各年の発売冊数を100%として、各グループの占める割合をグラフにすると下のようになります。これを見てみると、水色グループがゼロ年代序盤、赤グループが中盤、赤紫グループが終盤を多く占めているようです。平均ポジションの緑とか受賞作の黄色はいつでもそれほど変わらない感じですね。無個性グループ(というか、電撃文庫における主要単語「少女」「彼女」が出てこないグループ)は年が進むと次第に減っていくということでしょうか。
実のところ、クラスタリングのデータからは「グループに分けるとこんな感じ」という程度しか分からないので、クラスタリングで目星をつけた要素を次にちくちくと追いかけていって実際のところを確かめないといけません。それに、今回は全体をざっと見て目立つところだけをピックアップしているので、「頻度はそれほど高くないけどあるグループにしか現れない単語」みたいなものは見逃している可能性が高いです。そういうのはスクリプト作って自動的に回収するようにしないと、目で見てるだけだとなかなかわかりませんね。
しかしまあ、かなりぐだぐだになったけどそれなりにオチは着いたのかしら。次は他のレーベルを混ぜてみるとか、共起する単語の組で見てみるとか、動詞も入れてみるとか……。結構いくらでも思いつくなぁw
2010年12月26日 日曜日 [長年日記]
_ [Perl] ゼロ年代の電撃文庫をあらすじに出てくる名詞を使って分類してみる・改
イブ、クリスマスと風邪で寝込んで超ぐったりです。なんだこれ。
前回のクラスタリング、さすがにキーワードに年を混ぜ込んで分類するのはどうだろう(それでも差異は出たんだけどね)と思うので、きちんと年の追加なしのクラスタリング結果を年ごとに計数してみることにしました。
もうひとつ、各サブクラスターで特徴的だと思っていた単語が意外と一部のシリーズに偏ってたり、こそあど指示代名詞の影響がでかかったりしたので、単語リストからこそあど指示代名詞を抜いてクラスタリングして、さらに各サブクラスターのメンバー(シリーズ)ごとにどんな単語が使われているのかを出力してみました。
こそあど指示代名詞を削除した名詞リストはdengeki_2000-2009_noun_count2.tsvです。行列データの生成は前回のものからキーワードに年を追加していた部分をコメントアウトしたget_matrix_by_series_year3b.plを使います。これらを使って行列データの生成、樹形図の出力、サブクラスターごとの単語の使用頻度テーブルの出力までは前回と同じ。
$ perl get_matrix_by_series_year3b.pl dengeki_2000-2009_arasuji3.tsv dengeki_series.tsv dengeki_2000-2009_noun_count2.tsv dengeki_2000-2009_noun.tsv 1 > dengeki_2000-2009_series_matrix.txt $ R --vanilla -q < clustering_no_tfidf.R --args dengeki_2000-2009_series_matrix.txt dengeki_2000-2009_series_dendrogram.pdf 1 0.1 10 subcluster.txt result.txt $ perl count_subcluster_word.pl subcluster.txt dengeki_2000-2009_series_matrix.txt > dengeki_2000-2009_subcluster_word_count.txt
樹形図はこんな感じ。PDF版はこちら。サブクラスターごとの単語のカウント結果はdengeki_2000-2009_series_subcluster_word_count.txtになります。
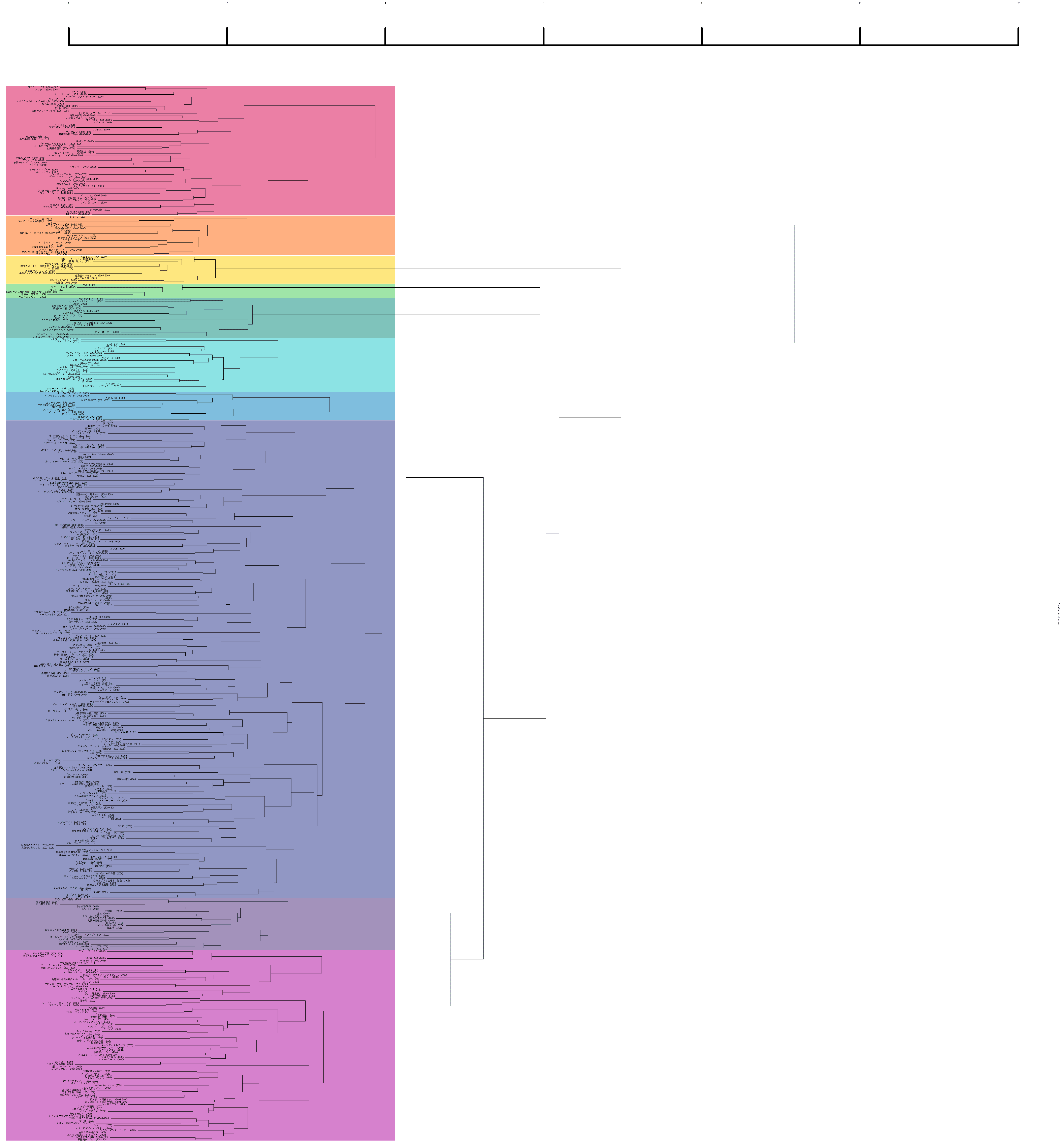
サブクラスターごとに主要な単語を抜き出すとこんな感じです。
| 単語 | 1(黄緑) | 2(藍) | 3(赤紫) | 4(赤) | 5(紫) | 6(水色) | 7(橙) | 8(青) | 9(緑) | 10(黄) | 合計 | ||||||||||
| 俺 | 39 | 6.5 | 10 | 0.0 | 26 | 0.3 | 0 | 0.0 | 0 | 0.0 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 0 | 0.0 | 78 |
| 人 | 6 | 1.0 | 282 | 1.4 | 93 | 1.1 | 297 | 5.4 | 14 | 0.6 | 20 | 0.9 | 12 | 0.7 | 3 | 0.3 | 29 | 1.7 | 13 | 1.1 | 769 |
| 彼女 | 3 | 0.5 | 96 | 0.5 | 134 | 1.7 | 52 | 0.9 | 12 | 0.5 | 19 | 0.8 | 25 | 1.5 | 2 | 0.2 | 11 | 0.6 | 27 | 2.3 | 381 |
| 二 | 0 | 0.0 | 118 | 0.6 | 54 | 0.7 | 126 | 2.3 | 6 | 0.3 | 10 | 0.4 | 8 | 0.5 | 1 | 0.1 | 14 | 0.8 | 4 | 0.3 | 341 |
| 二 人 | 0 | 0.0 | 67 | 0.3 | 28 | 0.3 | 110 | 2.0 | 4 | 0.2 | 8 | 0.3 | 4 | 0.2 | 1 | 0.1 | 12 | 0.7 | 2 | 0.2 | 236 |
| 一 | 2 | 0.3 | 105 | 0.5 | 40 | 0.5 | 94 | 1.7 | 5 | 0.2 | 4 | 0.2 | 10 | 0.6 | 0 | 0.0 | 10 | 0.6 | 7 | 0.6 | 277 |
| 少女 | 2 | 0.3 | 134 | 0.7 | 29 | 0.4 | 87 | 1.6 | 8 | 0.4 | 95 | 4.1 | 13 | 0.8 | 1 | 0.1 | 19 | 1.1 | 7 | 0.6 | 395 |
| 事件 | 0 | 0.0 | 80 | 0.4 | 27 | 0.3 | 35 | 0.6 | 44 | 2.0 | 3 | 0.1 | 3 | 0.2 | 0 | 0.0 | 4 | 0.2 | 11 | 0.9 | 207 |
| 世界 | 0 | 0.0 | 127 | 0.6 | 24 | 0.3 | 51 | 0.9 | 2 | 0.1 | 8 | 0.3 | 132 | 7.8 | 2 | 0.2 | 8 | 0.5 | 8 | 0.7 | 362 |
| 太郎 | 0 | 0.0 | 3 | 0.0 | 1 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 0.2 | 16 | 1.3 | 0 | 0.0 | 1 | 0.1 | 25 |
| 小説 | 3 | 0.5 | 23 | 0.1 | 12 | 0.1 | 16 | 0.3 | 2 | 0.1 | 2 | 0.1 | 2 | 0.1 | 16 | 1.3 | 43 | 2.5 | 6 | 0.5 | 125 |
| 阿智 太郎 | 0 | 0.0 | 3 | 0.0 | 1 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 0.2 | 15 | 1.3 | 0 | 0.0 | 1 | 0.1 | 24 |
| アニメ | 0 | 0.0 | 3 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 14 | 1.2 | 0 | 0.0 | 0 | 0.0 | 19 |
| 登場 | 2 | 0.3 | 100 | 0.5 | 31 | 0.4 | 32 | 0.6 | 4 | 0.2 | 3 | 0.1 | 4 | 0.2 | 13 | 1.1 | 10 | 0.6 | 11 | 0.9 | 210 |
| 大賞 | 1 | 0.2 | 15 | 0.1 | 8 | 0.1 | 15 | 0.3 | 2 | 0.1 | 2 | 0.1 | 3 | 0.2 | 1 | 0.1 | 49 | 2.9 | 12 | 1.0 | 108 |
| 電撃 | 1 | 0.2 | 43 | 0.2 | 19 | 0.2 | 21 | 0.4 | 2 | 0.1 | 3 | 0.1 | 3 | 0.2 | 5 | 0.4 | 46 | 2.7 | 6 | 0.5 | 149 |
| 受賞 | 1 | 0.2 | 16 | 0.1 | 8 | 0.1 | 17 | 0.3 | 0 | 0.0 | 2 | 0.1 | 3 | 0.2 | 1 | 0.1 | 37 | 2.2 | 6 | 0.5 | 91 |
| 受賞 作 | 1 | 0.2 | 8 | 0.0 | 5 | 0.1 | 9 | 0.2 | 0 | 0.0 | 0 | 0.0 | 3 | 0.2 | 0 | 0.0 | 21 | 1.2 | 5 | 0.4 | 52 |
| 僕 | 0 | 0.0 | 11 | 0.1 | 24 | 0.3 | 1 | 0.0 | 8 | 0.4 | 5 | 0.2 | 1 | 0.1 | 5 | 0.4 | 2 | 0.1 | 92 | 7.7 | 149 |
サブクラスターごとの特徴を前回の結果と比べてみると、単語リストに発売年を追加しなくてもそれほど変わらない感じです。
以上の結果から、各サブクラスターごとにその構成メンバーがそのサブクラスターの主要単語(同じサブクラスター内の半分以上のシリーズで使われており、シリーズ当たりの平均使用頻度が1以上、またはシリーズ当たりの平均使用頻度が0.5以上でそのサブクラスター内での使用頻度の全体の使用頻度に対する割合がそのサブクラスター中のシリーズ数の全シリーズ数に対する割合の5倍以上)を何回使っているのか、また各サブクラスターの本が2000-2009年に何冊ずつ出ているかを出力します。スクリプトはcount_subcluster_word3.plです。まあ、主要単語を決める数値はかなり適当に決めたので、もっと妥当な数値があるのかも。
$ perl count_subcluster_word3.pl dengeki_2000-2009_arasuji3.tsv dengeki_series.tsv dengeki_2000-2009_series_matrix.txt subcluster.txt > count_result.txt
出力されるファイルはcount_result.txtになります。このテキストファイルに、各サブクラスターのメンバーがそのサブクラスターの主要単語をあらすじで何回使っているかが出力されます。ラベルの単語はシリーズ当たりの平均使用頻度が0.5以上でそのサブクラスター内での使用頻度の全体の使用頻度に対する割合がそのサブクラスター中のシリーズ数の全シリーズ数に対する割合の5倍以上のものは<<>>、シリーズ当たりの平均使用頻度が1以上のものは<>で囲んであります。実は上のテーブルが前回と比べてえらくすっきりしているのは、この結果を反映して単語数を減らしているからです。
また、このファイルの最後には各サブクラスターに分類される本が2000年-2009年に何冊発売されているかも出力しています。最後の方めんどくさくなって年が2000年-2009年固定になっているので、そのうち入力ファイルから年を出すように変更しないとな……。前回と同じように各年に発売された本の冊数を100%として各サブクラスターに含まれる本の割合をグラフにすると以下のようになります。

藍色、赤紫、水色はそれぞれ、藍色が「人」、赤紫が「彼女」、水色が「少女」という電撃文庫のあらすじにおける頻出名詞トップ3をメインとするサブグループですが、それなりに年ごとの変動があるようです。あとはまあ、黄緑と黄色の一人称あらすじがだんだんと多くなってるなーって感じですかね。