
前回の続きです。今回はもう少し大きなデータでやってみましょう。2009年に発売された電撃文庫のあらすじを使ってみます。
grep '^2009' dengeki-bunko.utf-8.tsv > dengeki_2009.tsv perl get_amazon_data.pl dengeki_2009.tsv > dengeki_2009_arasuji.tsv
あらすじテキストの追加されたdengeki_2009_arasuji.tsvができます。現状、アマゾンでは2009年11月発売分にはあらすじが登録されておらず空欄になってしまいますが、手作業で追加するのもめんどくさいので放置します。ちなみに2000-2009年で107冊があらすじ未登録なのですよね……。ただし、クラスタリングする際にあらすじのない本が入っているとそれがひとかたまりになって出てくるので、あらすじのないデータは除いておきましょう。あらすじデータは11番目に入っているので、
perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" if $data[10];}' dengeki_2009_arasuji.tsv > dengeki_2009_arasuji2.tsvあらすじの入っていない本も別に分けておきましょうか。
perl -e 'while(<>){chomp;$line=$_;@data=split /\t/,$line;print "$line\n" unless $data[10];}' dengeki_2009_arasuji.tsv > dengeki_2009_arasuji_no_data.tsvdengeki_2009_arasuji2.tsvを使って引き続き、前回と同様に樹形図の出力までやってみましょう。なお、このファイル中の書名は元データのままだと樹形図を書く際に一部の書名が表示されないため、ダッシュ記号はハイフンに置換してあります。また、今回、データが多くなったので、ラベル文字の大きさや線の太さを引数で変更できるようにスクリプトを変更しました。スクリプトは前回とファイル名は同じclustering.Rです。
perl split_sentence.pl dengeki_2009_arasuji2.tsv > dengeki_2009_sentence.tsv perl get_noun_list.pl dengeki_2009_sentence.tsv > dengeki_2009_noun.tsv perl count_noun_with_sub.pl dengeki_2009_noun.tsv > dengeki_2009_noun_count.tsv perl get_matrix_data.pl dengeki_2009_arasuji.tsv dengeki_2009_noun_count.tsv dengeki_2009_noun.tsv > dengeki_2009_matrix.txt R --vanilla -q < clustering.R --args dengeki_2009_matrix.txt dengeki_2009_dendorogram.pdf 3 0.3
clustering.Rの3番目の引数3がラベル文字の大きさ、4番目の引数0.3が線の太さになります。下の図のような樹形図が出力されます。
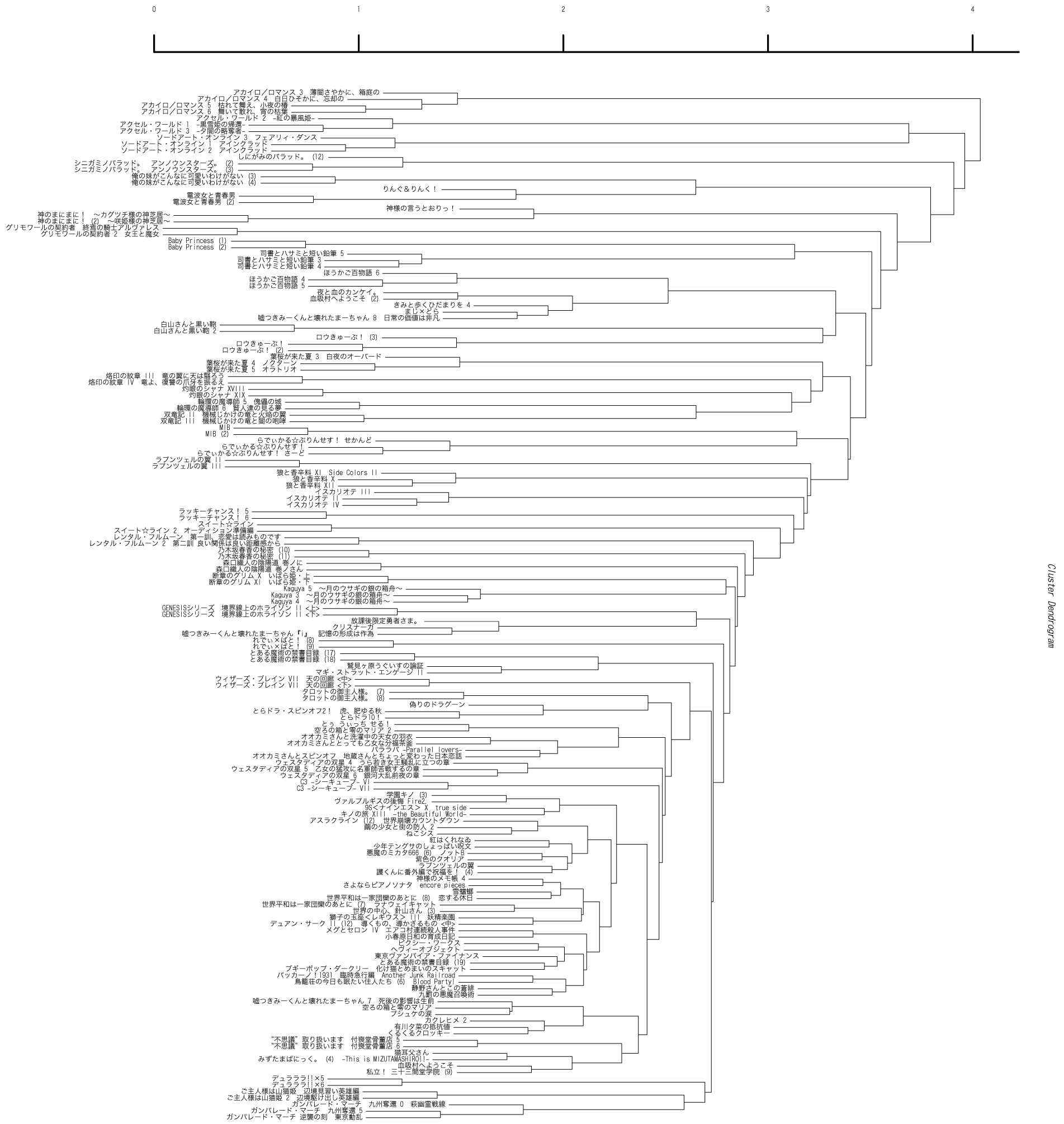
前回の樹形図と比べると、なんだかバランスが変ですね?図をよく見てみると、同じシリーズが末端の方で分岐していて、別シリーズ同士は非常に長い枝で分かれているのがわかります。また、シリーズがいくつかでひとかたまりの枝を作らず、各シリーズの枝が一本ずつ本体から分岐しています。これはどういうことかというと、同じシリーズの本同士は似ているけど、別シリーズの本同士はほとんど比べ様がないほど似ていないということを表しています。これではクラスター解析をする意味がないですね。さてどうしたものか。
前回、TF*IDFという処理について説明しました。特定のテキストデータのみに出現する単語は重要で、全体にまんべんなく出てくる単語は重要でないといったように、単語ごとの重要度に応じて重み付けをする処理でした。そこで、TF*IDFの処理を外して多くの本で共通する単語の重要度を上げてみます。処理としてはclustering.RでのTF*IDFの処理をスキップするだけで、スクリプトはclustering_no_tfidf.Rになります。
R --vanilla -q < clustering_no_tfidf.R --args dengeki_2009_matrix.txt dengeki_2009_dendorogram.pdf
今回は下の図のような樹形図が出力されます。
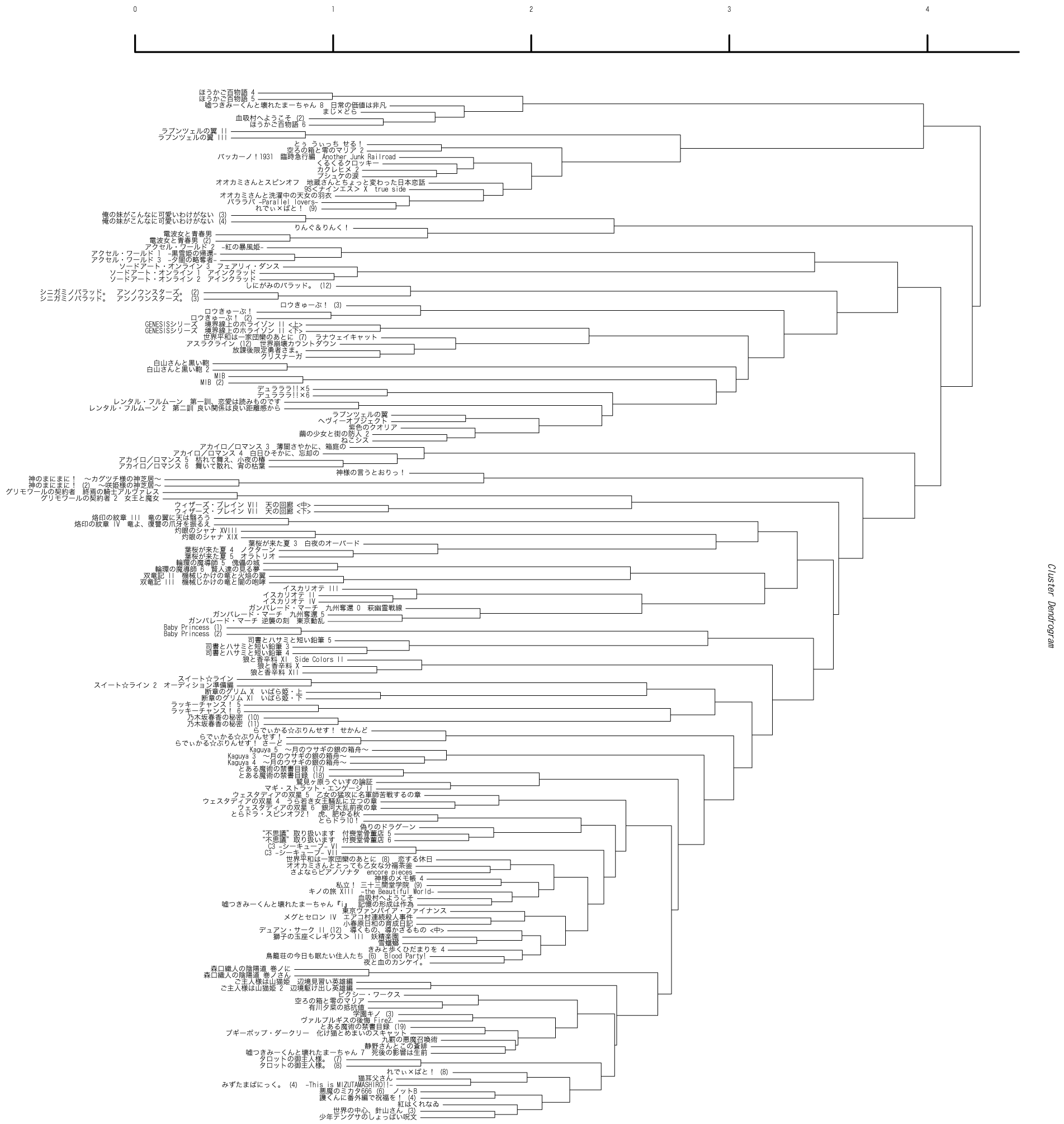
今回は、前回と比べるとかなり固まりができてきましたね。
次に、どっちみちよく似てるもの同士になってしまう同じシリーズの本はひとまとめにしてみましょう。1タイトルあたりのデータ量を増やしてみようという考えです。処理としては、シリーズ名-書名の対応関係を作って、書名単位で集計していたのをシリーズ単位で集計するだけです。というわけで、まずはシリーズ名-書名の対応データを作らなければいけません。基本的に書名の一番最初に出てくるスペースから右を消せばだいたいシリーズ名になりますが、例外もあるので最終的には手作業になります。dengeki_series.tsvです。頑張って2000-2009年のシリーズ名-書名対応データを作りました!このデータ中の書名はdengeki_2009_arasuji2.tsv中の書名と同一でないといけません。
処理に使うデータはこれで全部揃っているので、クラスタリングに使う行列データをシリーズ単位で出力するスクリプトを用意すれば準備完了です。使うスクリプトはget_matrix_by_series.plです。
perl get_matrix_by_series.pl dengeki_2009_arasuji.tsv dengeki_series.tsv dengeki_2009_noun_count.tsv dengeki_2009_noun.tsv 1 > dengeki_2009_series_matrix.txt R --vanilla -q < clustering_no_tfidf.R --args dengeki_2009_series_matrix.txt dengeki_2009_series_dendorogram.pdf
今回、また引数が増えてますね。2番目の引数にシリーズ-書名データが入って、さらに5番目の引数に整数が入ります。この数字は、全体でこの数字以下の使用回数の単語は無視する、という指定に使います。ここでは、これまで通り全体で1回しか出てこない単語は無視しましょう。次のような樹形図が出力されます。

うん、1つめの樹形図と比べると、かなりバランスが良くなった感じですね。これでとりあえずシリーズごとの分類ができたわけですが、ここからさらにこの図のそれぞれの枝の固まりの特徴を、その枝のシリーズでの単語の使用の特徴として調べていくと重要な単語が何なのか見えてくるというわけです。
少し、使われている単語の影響をみてみましょう。下の左側は上の樹形図にサブクラスターごとに色をつけたものです。これに対して右側は、クラスタリングの際にTF*IDF処理を行ったものになります。シリーズ名の色分けは左側と同じ色になるように塗っています。左右で局所的な枝分かれ構造は保持されていますが、全体がばらばらになっていることがわかります。

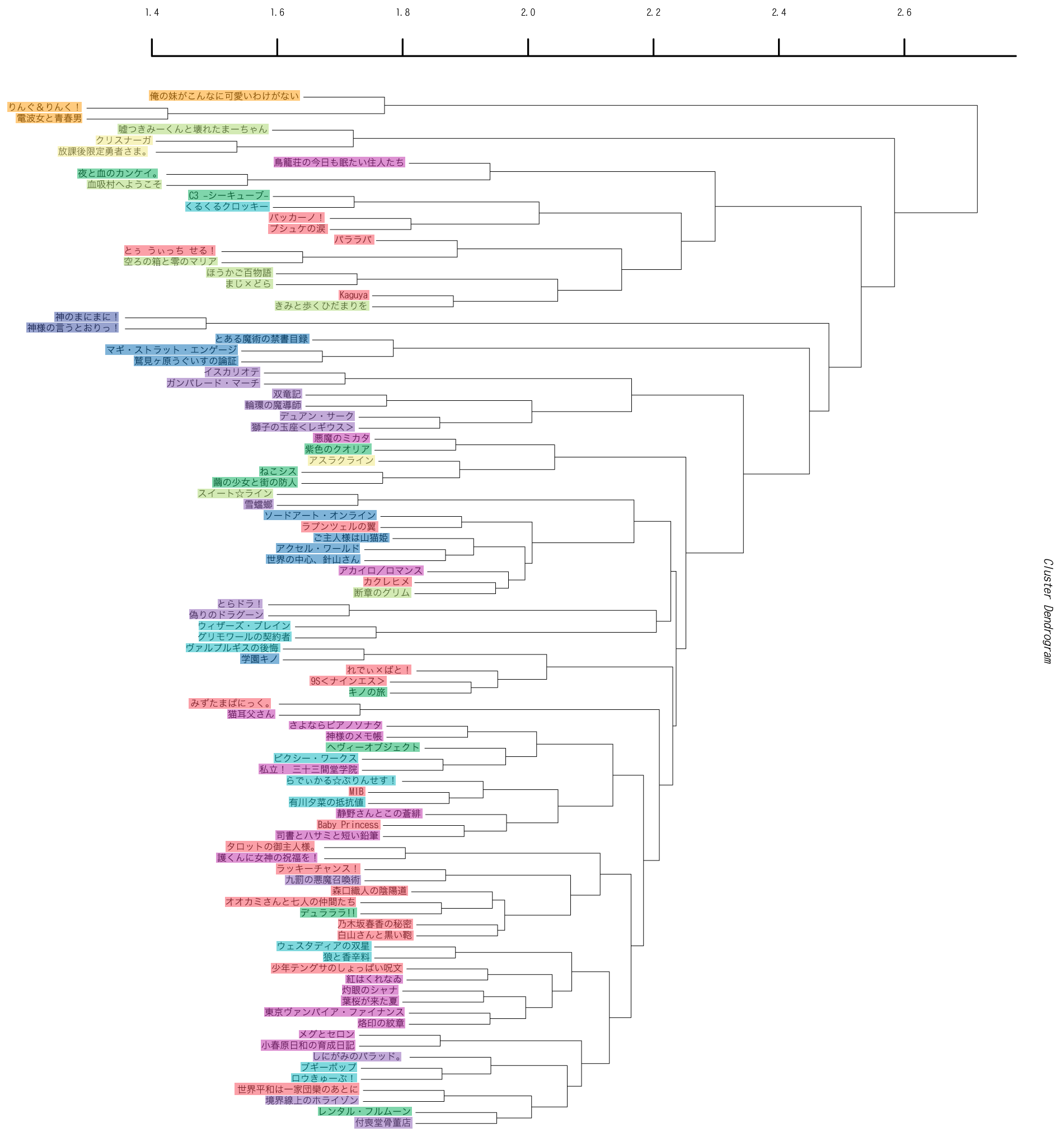
TF*IDF処理を行うと、広い範囲で出現する単語の重要度が下がります。逆に言えば、TF*IDF処理を行っていない左側の樹形図では、広い範囲で出現する単語の重要度が上がっている事になります。つまり、左側の樹形図で右側には出てこないクラスターを作らせているのは、「彼女」とか「少女」といった非常によく出てくる単語ということになります。