
本日は予定を変更してクラスター解析なぞやってみようと思います。
クラスター解析とは、データのセットの中から似たもの同士をグループにまとめていく手法、と思ってください。
昨日作成した「とある魔術の禁書目録」のあらすじに登場する名詞のリストを使って、「とある魔術の禁書目録」の各巻を似てるもの同士グループ分けしてみます。
テキストデータの解析には、それぞれのテキストデータにどんな単語がどれだけ登場するかを比較するのが常套手段です。そのために、テキストデータごとにどの単語が何回出てきたかという情報をベクトルで表現します。さらに、特定のテキストデータのみに出現する単語は重要で、全体にまんべんなく出てくる単語は重要でないといったように、単語ごとの重要度に応じて重み付けを行います。これには、TF*IDFという方法がよく用いられます。最後にベクトルの大きさがすべて1になるように正規化を行って、各テキストデータのベクトルの向きが近いもの同士をグループにしていくとテキストデータの分類ができるという寸法です。
では、昨日作った「とある魔術の禁書目録」の各巻のあらすじに登場する名詞のリストから各巻のあらすじの文書ベクトルを作ってみます。使うスクリプトはget_matrix_data.plになります。
perl get_matrix_data.pl toaru.tsv toaru_noun_count2.tsv toaru_noun.tsv > toaru_matrix.txt
今回は入力ファイルを3つも使うので、順番を間違えないようにしてください。最初に大元のデータからISBNコードと書名の対応データを、count_noun_with_sub.plの出力ファイルから名詞とその名詞のサブグループである複合名詞のリストの対応データを、get_noun_list.plの出力ファイルからISBNコードとその本のあらすじでの各名詞の出現回数の対応データをそれぞれ取ってきて、各巻ごとにどの名詞が何回出てきたか(カウント方式は改良型)の行列データtoaru_matrix.txtを出力します。このファイルを見てみると、1行目が名詞の見出し欄になっていて、2行目以降に各巻ごとに見出し欄の名詞があらすじに何回登場したかが表示されているのがわかるかと思います。この2行目以降の数字の羅列がそれぞれの本の文書ベクトルというわけです。なお、全体で1回しか出てこない単語は似た者同士のグループ分けの役には立たないので外してあります。
ここまでで文書ベクトルの組が行列の形でできあがったので、これを元にクラスター解析を行います。クラスター解析のような統計処理にはRという統計解析システムがよく使われます。Rについては公式サイトからダウンロードしてインストールしてみてください。Mac OS XではMacPortsでインストールするのもよいでしょう。
正直、Rについては仕事に使うのでクラスタリングのためのスクリプトをひたすらサンプルスクリプトのコピペで作っただけなので、さっぱり分かってません。まあ、その時作ったclustering.Rを使って先ほどの行列データtoaru_matrix.txtのクラスタリングを行い、その結果を樹形図で表示してみましょう。
R --vanilla -q < clustering.R --args toaru_matrix.txt toaru_dendorogram.pdf
Rのスクリプト実行ってわけわからんよな……。ともかくこれで、クラスタリングの結果がtoaru_dendorogram.pdfというファイルに出力されます。PNGに変換したものはこんな感じです。
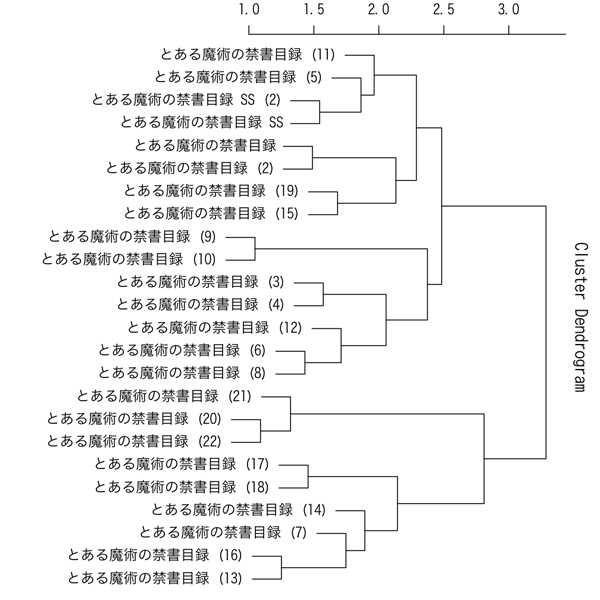
この図、右端を根っこ、左端の書名が書いてある部分を葉とすると、なんとなく木のように見えると思います。そのため、この図は樹形図とかデンドログラムとか言われます。この樹形図では、枝分かれの近い葉同士がお互いによく似ている者同士、枝分かれが遠くなるほど両者の違いが大きくなっていく、というように表現されています。
それでは実際に樹形図を見てみましょう。分かりやすいところでは、6巻・8巻は黒子、9巻・10巻は大覇星祭、13巻・16巻は神の右席、15巻・19巻は学園暗部、17巻・18巻は英国、20-22巻はフィアンマさんという感じで近いもの同士は何となくその理由がわかると思います。また、下側の塊(7・13・14・16・17・18・20・21・22巻)はローマ正教が共通キーワードなんだなーとか、その上の塊(3・4・6・8・9・10・12巻)は御坂さん登場回だなーとか、グループ分けの基準がなんとなく見えるんじゃないかと。
こんな感じで、クラスター解析ってものを使うとテキストデータの分類ができますよ、という紹介でした。