
昨日作った、2009年発売の電撃文庫のあらすじから抽出した名詞によるシリーズの分類がどのような特徴によるものかを見てみましょう。
Rを使ったクラスター解析では、単に樹形図を出力するだけではなく、クラスター解析の結果をいくつのサブクラスターに分割するか設定し、各サブクラスターには何が含まれるか、といったことももちろん出力できます。そのように書き換えたスクリプトはclustering_no_tfidf.Rになります。
R --vanilla -q < clustering_no_tfidf.R --args dengeki_2009_series_matrix.txt dengeki_2009_series_dendorogram.pdf 4 0.3 10 subcluster.txt result.txt
今回は引数が3個増えて7個になっています。5番目の引数はクラスター解析の結果をいくつのサブクラスターに分割するかの指定、6番目の引数はクラスター解析にかけた各要素がどのサブクラスターに含まれるかの結果の出力ファイル、7番目の引数は樹形図の元になっている数値データの出力ファイルです。最後の出力ファイルはとりあえずは必要ないのですが、まあ一応出しておきます。上のコマンドでは、クラスタリングの結果を10個に分割するよう指定しています。実際にどこで分割されるかというと、下の図の赤のラインになります。なお、樹形図自体は昨日のものと同じですが、都合により色の塗り分けが若干変わっています。
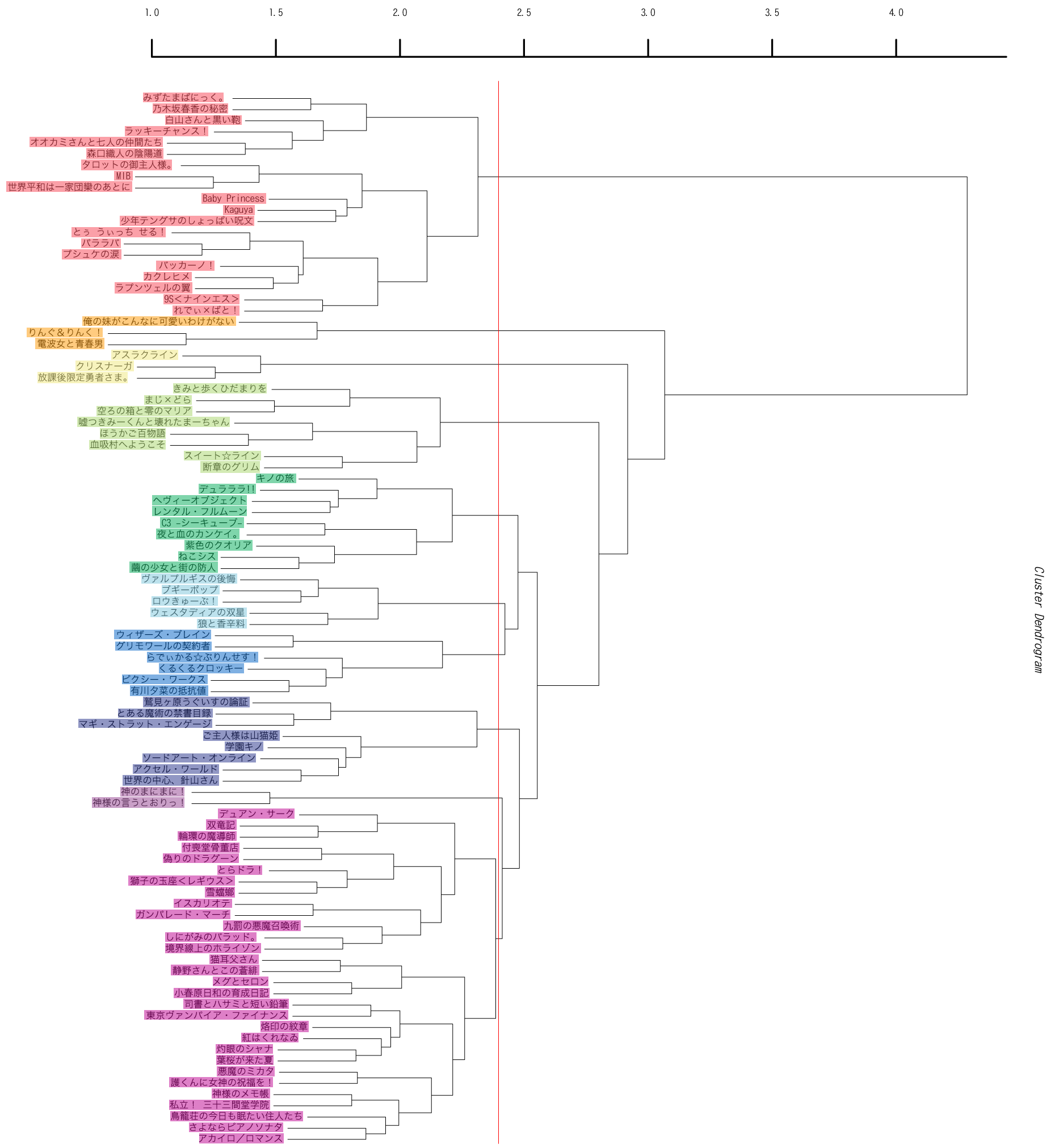
subcluster.txtにはdengeki_2009_series_matrix.txtの1列目のシリーズ名が上から順に1〜10のどのサブクラスターに入るかが出力されます。
ここまで来れば、後は各サブクラスターごとにdengeki_2009_series_matrix.txtからどの単語が何回出てきたかを集計してやれば、各サブクラスターで使用された単語の特徴がわかるはずです。というわけで、count_subcluster_word.plで集計してみましょう。
perl count_subcluster_word.pl subcluster.txt dengeki_2009_series_matrix.txt > dengeki_2009_subcluster_word_count.txt
出力されたdengeki_2009_subcluster_word_count.txtには、1列目に単語、2列めにサブクラスター1での使用回数、3列目に2列目の数値をサブクラスター1に含まれるシリーズ数で割った数値...というようにRの実行時に指定したサブクラスターの数だけ数値が出力されています。サブクラスターの何番は樹形図のどこの枝かというのは行列データ(dengeki_2009_series_matrix.txt)の1列目のラベルとsubcluster.txtと樹形図を比較しないといけないのでちとめんどくさいのですが、とりあえず大事そうな部分を抜き出した結果が下のテーブルになります。※見直してみるとどうにもデータのピックアップがいまいちだったので修正しました(2010/12/18 16:20)。
| 単語 | 合計 | 1(赤) | 2(緑) | 3(黄緑) | 4(青) | 5(藍) | 6(赤紫) | 7(橙) | 8(黄) | 9(水色) | 10(紫) | ||||||||||
| 人 | 141 | 80 | 4.0 | 4 | 0.4 | 4 | 0.5 | 8 | 1.3 | 11 | 1.4 | 20 | 0.7 | 2 | 0.7 | 0 | 0.0 | 4 | 0.8 | 8 | 4.0 |
| 二 | 52 | 29 | 1.5 | 2 | 0.2 | 4 | 0.5 | 2 | 0.3 | 5 | 0.6 | 8 | 0.3 | 0 | 0.0 | 1 | 0.3 | 1 | 0.2 | 0 | 0.0 |
| 二 人 | 32 | 23 | 1.2 | 0 | 0.0 | 1 | 0.1 | 1 | 0.2 | 3 | 0.4 | 4 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 人間 | 26 | 0 | 0.0 | 17 | 1.9 | 3 | 0.4 | 0 | 0.0 | 0 | 0.0 | 5 | 0.2 | 0 | 0.0 | 1 | 0.3 | 0 | 0.0 | 0 | 0.0 |
| 少女 | 63 | 15 | 0.8 | 15 | 1.7 | 2 | 0.3 | 4 | 0.7 | 6 | 0.8 | 10 | 0.3 | 3 | 1.0 | 1 | 0.3 | 7 | 1.4 | 0 | 0.0 |
| 僕 | 21 | 1 | 0.1 | 0 | 0.0 | 19 | 2.4 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 魔法 | 17 | 1 | 0.1 | 0 | 0.0 | 1 | 0.1 | 15 | 2.5 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 彼女 | 74 | 25 | 1.3 | 2 | 0.2 | 12 | 1.5 | 12 | 2.0 | 7 | 0.9 | 10 | 0.3 | 1 | 0.3 | 1 | 0.3 | 4 | 0.8 | 0 | 0.0 |
| 魔法 書 | 11 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 11 | 1.8 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 秘密 | 21 | 5 | 0.3 | 0 | 0.0 | 0 | 0.0 | 8 | 1.3 | 0 | 0.0 | 6 | 0.2 | 1 | 0.3 | 1 | 0.3 | 0 | 0.0 | 0 | 0.0 |
| 彼 | 28 | 4 | 0.2 | 1 | 0.1 | 2 | 0.3 | 1 | 0.2 | 14 | 1.8 | 6 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 姫 | 18 | 3 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 12 | 1.5 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.5 |
| 魔術 | 10 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 10 | 1.3 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 謎 | 27 | 5 | 0.3 | 3 | 0.3 | 3 | 0.4 | 2 | 0.3 | 9 | 1.1 | 5 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 俺 | 23 | 3 | 0.2 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 19 | 6.3 | 0 | 0.0 | 1 | 0.2 | 0 | 0.0 |
| さん | 49 | 25 | 1.3 | 1 | 0.1 | 12 | 1.5 | 0 | 0.0 | 2 | 0.3 | 0 | 0.0 | 8 | 2.7 | 0 | 0.0 | 1 | 0.2 | 0 | 0.0 |
| 小説 | 16 | 2 | 0.1 | 1 | 0.1 | 2 | 0.3 | 0 | 0.0 | 3 | 0.4 | 1 | 0.0 | 5 | 1.7 | 0 | 0.0 | 0 | 0.0 | 2 | 1.0 |
| 青春 | 7 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.2 | 1 | 0.1 | 0 | 0.0 | 5 | 1.7 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 女 | 21 | 2 | 0.1 | 6 | 0.7 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 3 | 0.1 | 4 | 1.3 | 1 | 0.3 | 4 | 0.8 | 0 | 0.0 |
| 相談 | 6 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 1.3 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 布団 | 4 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 1.3 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 |
| 世界 | 38 | 4 | 0.2 | 5 | 0.6 | 1 | 0.1 | 4 | 0.7 | 4 | 0.5 | 7 | 0.2 | 0 | 0.0 | 12 | 4.0 | 1 | 0.2 | 0 | 0.0 |
| ぼく | 9 | 0 | 0.0 | 0 | 0.0 | 3 | 0.4 | 0 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 5 | 1.7 | 0 | 0.0 | 0 | 0.0 |
| たち | 77 | 21 | 1.1 | 2 | 0.2 | 10 | 1.3 | 5 | 0.8 | 6 | 0.8 | 14 | 0.5 | 0 | 0.0 | 2 | 0.7 | 17 | 3.4 | 0 | 0.0 |
| 王国 | 9 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 7 | 1.4 | 0 | 0.0 |
| それ | 39 | 10 | 0.5 | 3 | 0.3 | 3 | 0.4 | 2 | 0.3 | 2 | 0.3 | 11 | 0.4 | 0 | 0.0 | 0 | 0.0 | 7 | 1.4 | 1 | 0.5 |
| ー | 13 | 1 | 0.1 | 0 | 0.0 | 2 | 0.3 | 1 | 0.2 | 0 | 0.0 | 1 | 0.0 | 2 | 0.7 | 0 | 0.0 | 6 | 1.2 | 0 | 0.0 |
| 狼 | 6 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 6 | 1.2 | 0 | 0.0 |
| 神様 | 12 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 11 | 5.5 |
| ヘッポコ | 5 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 5 | 2.5 |
| 神 | 8 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 2.0 |
| 様 | 6 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 0 | 0.0 | 4 | 2.0 |
こうして見ると、なかなか奇麗に分かれてますな。赤は「二人」クラスター、オレンジは「俺」クラスター、黄は「世界・ぼく」クラスター、黄緑は「僕」クラスター、緑は「人間」クラスター、水色はちょっと微妙ですが「○○たち・王国」クラスター、青は「魔法・秘密」クラスター、藍は「彼・姫・魔術・謎」クラスター、紫は「神様」クラスター、赤紫はそのどれでもないものって感じの分類になっているようです。このクラスタリングではTF*IDFを行っていないので、ここに出てくるような使用頻度の大きな単語がそのままクラスターの形成に影響を与えているわけです。TF*IDFを行ってクラスタリングした場合は、補正後の数値を算出しないと実際の影響は見られない事に注意してください。また、実際にはここに出した以外の様々な単語の影響があるわけですが、ここでは思いっきり単純化してみました。
次は、ゼロ年代の本全部を対象にしてやってみましょうかね?