
イブ、クリスマスと風邪で寝込んで超ぐったりです。なんだこれ。
前回のクラスタリング、さすがにキーワードに年を混ぜ込んで分類するのはどうだろう(それでも差異は出たんだけどね)と思うので、きちんと年の追加なしのクラスタリング結果を年ごとに計数してみることにしました。
もうひとつ、各サブクラスターで特徴的だと思っていた単語が意外と一部のシリーズに偏ってたり、こそあど指示代名詞の影響がでかかったりしたので、単語リストからこそあど指示代名詞を抜いてクラスタリングして、さらに各サブクラスターのメンバー(シリーズ)ごとにどんな単語が使われているのかを出力してみました。
こそあど指示代名詞を削除した名詞リストはdengeki_2000-2009_noun_count2.tsvです。行列データの生成は前回のものからキーワードに年を追加していた部分をコメントアウトしたget_matrix_by_series_year3b.plを使います。これらを使って行列データの生成、樹形図の出力、サブクラスターごとの単語の使用頻度テーブルの出力までは前回と同じ。
$ perl get_matrix_by_series_year3b.pl dengeki_2000-2009_arasuji3.tsv dengeki_series.tsv dengeki_2000-2009_noun_count2.tsv dengeki_2000-2009_noun.tsv 1 > dengeki_2000-2009_series_matrix.txt $ R --vanilla -q < clustering_no_tfidf.R --args dengeki_2000-2009_series_matrix.txt dengeki_2000-2009_series_dendrogram.pdf 1 0.1 10 subcluster.txt result.txt $ perl count_subcluster_word.pl subcluster.txt dengeki_2000-2009_series_matrix.txt > dengeki_2000-2009_subcluster_word_count.txt
樹形図はこんな感じ。PDF版はこちら。サブクラスターごとの単語のカウント結果はdengeki_2000-2009_series_subcluster_word_count.txtになります。
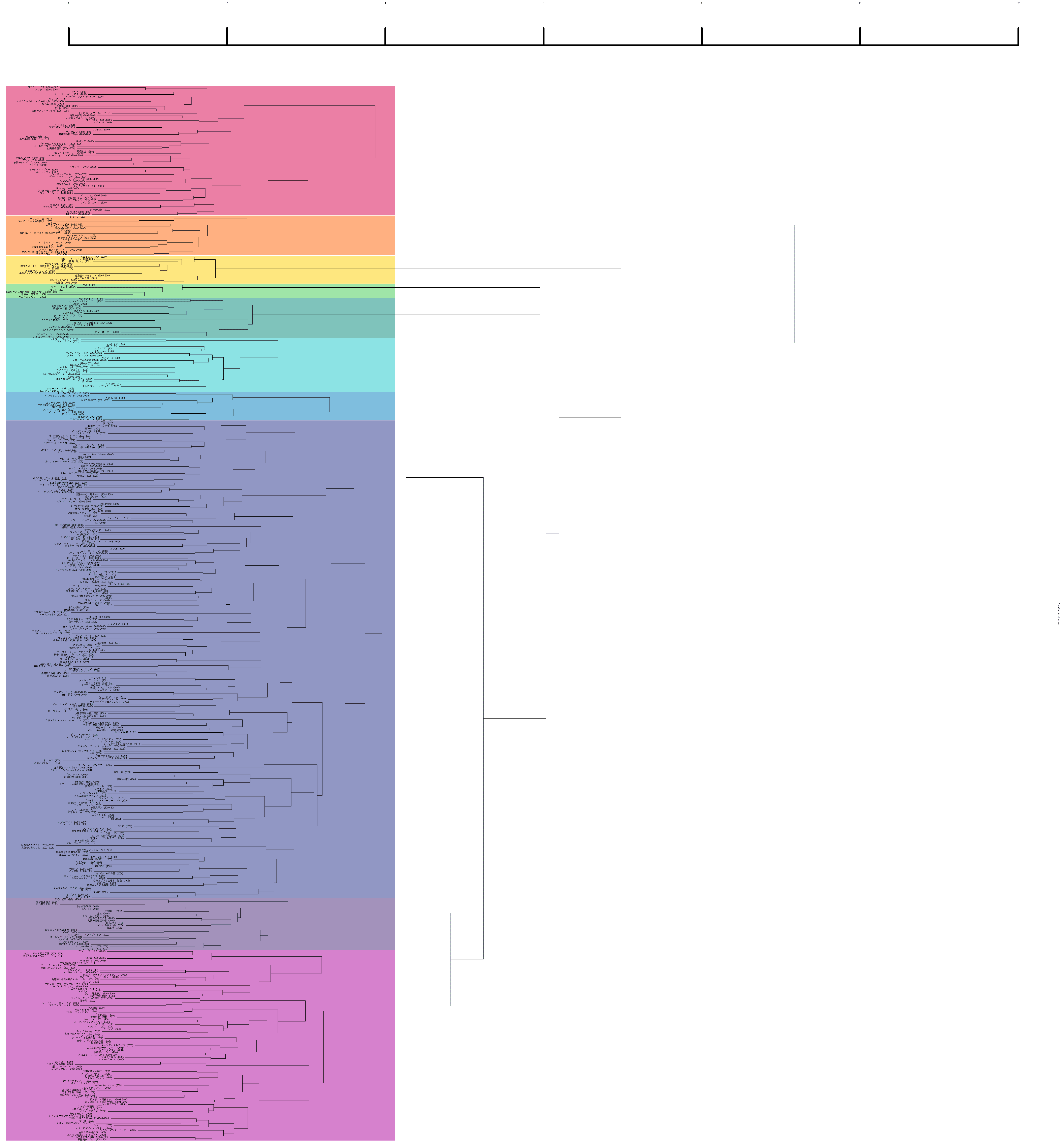
サブクラスターごとに主要な単語を抜き出すとこんな感じです。
| 単語 | 1(黄緑) | 2(藍) | 3(赤紫) | 4(赤) | 5(紫) | 6(水色) | 7(橙) | 8(青) | 9(緑) | 10(黄) | 合計 | ||||||||||
| 俺 | 39 | 6.5 | 10 | 0.0 | 26 | 0.3 | 0 | 0.0 | 0 | 0.0 | 2 | 0.1 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 0 | 0.0 | 78 |
| 人 | 6 | 1.0 | 282 | 1.4 | 93 | 1.1 | 297 | 5.4 | 14 | 0.6 | 20 | 0.9 | 12 | 0.7 | 3 | 0.3 | 29 | 1.7 | 13 | 1.1 | 769 |
| 彼女 | 3 | 0.5 | 96 | 0.5 | 134 | 1.7 | 52 | 0.9 | 12 | 0.5 | 19 | 0.8 | 25 | 1.5 | 2 | 0.2 | 11 | 0.6 | 27 | 2.3 | 381 |
| 二 | 0 | 0.0 | 118 | 0.6 | 54 | 0.7 | 126 | 2.3 | 6 | 0.3 | 10 | 0.4 | 8 | 0.5 | 1 | 0.1 | 14 | 0.8 | 4 | 0.3 | 341 |
| 二 人 | 0 | 0.0 | 67 | 0.3 | 28 | 0.3 | 110 | 2.0 | 4 | 0.2 | 8 | 0.3 | 4 | 0.2 | 1 | 0.1 | 12 | 0.7 | 2 | 0.2 | 236 |
| 一 | 2 | 0.3 | 105 | 0.5 | 40 | 0.5 | 94 | 1.7 | 5 | 0.2 | 4 | 0.2 | 10 | 0.6 | 0 | 0.0 | 10 | 0.6 | 7 | 0.6 | 277 |
| 少女 | 2 | 0.3 | 134 | 0.7 | 29 | 0.4 | 87 | 1.6 | 8 | 0.4 | 95 | 4.1 | 13 | 0.8 | 1 | 0.1 | 19 | 1.1 | 7 | 0.6 | 395 |
| 事件 | 0 | 0.0 | 80 | 0.4 | 27 | 0.3 | 35 | 0.6 | 44 | 2.0 | 3 | 0.1 | 3 | 0.2 | 0 | 0.0 | 4 | 0.2 | 11 | 0.9 | 207 |
| 世界 | 0 | 0.0 | 127 | 0.6 | 24 | 0.3 | 51 | 0.9 | 2 | 0.1 | 8 | 0.3 | 132 | 7.8 | 2 | 0.2 | 8 | 0.5 | 8 | 0.7 | 362 |
| 太郎 | 0 | 0.0 | 3 | 0.0 | 1 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 0.2 | 16 | 1.3 | 0 | 0.0 | 1 | 0.1 | 25 |
| 小説 | 3 | 0.5 | 23 | 0.1 | 12 | 0.1 | 16 | 0.3 | 2 | 0.1 | 2 | 0.1 | 2 | 0.1 | 16 | 1.3 | 43 | 2.5 | 6 | 0.5 | 125 |
| 阿智 太郎 | 0 | 0.0 | 3 | 0.0 | 1 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 3 | 0.2 | 15 | 1.3 | 0 | 0.0 | 1 | 0.1 | 24 |
| アニメ | 0 | 0.0 | 3 | 0.0 | 0 | 0.0 | 1 | 0.0 | 0 | 0.0 | 0 | 0.0 | 1 | 0.1 | 14 | 1.2 | 0 | 0.0 | 0 | 0.0 | 19 |
| 登場 | 2 | 0.3 | 100 | 0.5 | 31 | 0.4 | 32 | 0.6 | 4 | 0.2 | 3 | 0.1 | 4 | 0.2 | 13 | 1.1 | 10 | 0.6 | 11 | 0.9 | 210 |
| 大賞 | 1 | 0.2 | 15 | 0.1 | 8 | 0.1 | 15 | 0.3 | 2 | 0.1 | 2 | 0.1 | 3 | 0.2 | 1 | 0.1 | 49 | 2.9 | 12 | 1.0 | 108 |
| 電撃 | 1 | 0.2 | 43 | 0.2 | 19 | 0.2 | 21 | 0.4 | 2 | 0.1 | 3 | 0.1 | 3 | 0.2 | 5 | 0.4 | 46 | 2.7 | 6 | 0.5 | 149 |
| 受賞 | 1 | 0.2 | 16 | 0.1 | 8 | 0.1 | 17 | 0.3 | 0 | 0.0 | 2 | 0.1 | 3 | 0.2 | 1 | 0.1 | 37 | 2.2 | 6 | 0.5 | 91 |
| 受賞 作 | 1 | 0.2 | 8 | 0.0 | 5 | 0.1 | 9 | 0.2 | 0 | 0.0 | 0 | 0.0 | 3 | 0.2 | 0 | 0.0 | 21 | 1.2 | 5 | 0.4 | 52 |
| 僕 | 0 | 0.0 | 11 | 0.1 | 24 | 0.3 | 1 | 0.0 | 8 | 0.4 | 5 | 0.2 | 1 | 0.1 | 5 | 0.4 | 2 | 0.1 | 92 | 7.7 | 149 |
サブクラスターごとの特徴を前回の結果と比べてみると、単語リストに発売年を追加しなくてもそれほど変わらない感じです。
以上の結果から、各サブクラスターごとにその構成メンバーがそのサブクラスターの主要単語(同じサブクラスター内の半分以上のシリーズで使われており、シリーズ当たりの平均使用頻度が1以上、またはシリーズ当たりの平均使用頻度が0.5以上でそのサブクラスター内での使用頻度の全体の使用頻度に対する割合がそのサブクラスター中のシリーズ数の全シリーズ数に対する割合の5倍以上)を何回使っているのか、また各サブクラスターの本が2000-2009年に何冊ずつ出ているかを出力します。スクリプトはcount_subcluster_word3.plです。まあ、主要単語を決める数値はかなり適当に決めたので、もっと妥当な数値があるのかも。
$ perl count_subcluster_word3.pl dengeki_2000-2009_arasuji3.tsv dengeki_series.tsv dengeki_2000-2009_series_matrix.txt subcluster.txt > count_result.txt
出力されるファイルはcount_result.txtになります。このテキストファイルに、各サブクラスターのメンバーがそのサブクラスターの主要単語をあらすじで何回使っているかが出力されます。ラベルの単語はシリーズ当たりの平均使用頻度が0.5以上でそのサブクラスター内での使用頻度の全体の使用頻度に対する割合がそのサブクラスター中のシリーズ数の全シリーズ数に対する割合の5倍以上のものは<<>>、シリーズ当たりの平均使用頻度が1以上のものは<>で囲んであります。実は上のテーブルが前回と比べてえらくすっきりしているのは、この結果を反映して単語数を減らしているからです。
また、このファイルの最後には各サブクラスターに分類される本が2000年-2009年に何冊発売されているかも出力しています。最後の方めんどくさくなって年が2000年-2009年固定になっているので、そのうち入力ファイルから年を出すように変更しないとな……。前回と同じように各年に発売された本の冊数を100%として各サブクラスターに含まれる本の割合をグラフにすると以下のようになります。

藍色、赤紫、水色はそれぞれ、藍色が「人」、赤紫が「彼女」、水色が「少女」という電撃文庫のあらすじにおける頻出名詞トップ3をメインとするサブグループですが、それなりに年ごとの変動があるようです。あとはまあ、黄緑と黄色の一人称あらすじがだんだんと多くなってるなーって感じですかね。